Chapter 7 Relationships with Categorical Variables
Independent and Dependent Variables, T-test, Chi-square
Learning Outcomes:
- Learn to arrange variables as independent and dependent variables
- Learn to test for statistical significance in relationships between a categorical variable and one other variable
- Understand how to interpret outputs from t-tests and the chi-square test
Today’s Learning Tools:
Total number of activities: 11
Data:
- British Crime Survey (BCS)
Packages:
dplyreffsizeggplot2gmodelshavenhereskimrvcdExtra
Functions introduced (and packages to which they belong)
chisq.test(): Produces the chi-square test (base R)cohen.d(): Computes the Cohen’s d and Hedges’g effect size statistics (effsize)CrossTable(): Produces contingency tables (gmodels)fisher.test(): Produces Fisher’s exact test (base R)n(): Count observations withinsummarize(),mutate(),filter()(dplyr)read_dta(): Imports a .dta Stata file (haven)t.test(): Performs one and two sample t-tests on vectors of data (base R)var.test(): Performs an F-test to compare the variances of two samples from normal populations (base R)with(): Evaluates an expression, often to specify data you want to use (base R)
7.1 Associating with Categorical Variables
We are familiar with categorical variables. They have a nominal or ordinal level of measurement, and can be binary – have only two possible values. In R, these variables are encoded as a factor class, and for shorthand, are referred to as factors. (See Lesson 2, section 2.4.1.1 .)
In inferential statistics, sometimes we want to make predictions about relationships with factors. For example, we want to understand the relationship between sex and fear of crime. Perhaps we think males will have lower levels of fear of crime than females would have. The variable, sex, in this case, is a binary factor with the two categories, male and female, whereas fear of crime is a numeric variable.
Today, we learn how to conduct more inferential statistical analyses, but specifically with categorical variables.
7.1.1 Activity 1: Our R prep routine
Before we start, we do the following:
Open up our existing
RprojectInstall and load the required packages listed above with exception to
vcdExtra; the reason isvcdExtrawill interfere with the packagedplyr(see Lesson 1, section 1.3.3 on masking):Download from Blackboard and load into
Rthe British Crime Survey (BCS) dataset (bcs_2007_8_teaching_data_unrestricted.dta ). Be mindful of its data format because it will require certain codes and packages. Name this data frameBCS0708.Get to know the data with the
View()function.
7.2 Today’s 3
We further our understanding of inferential statistics by learning more about variables and a couple of new statistical analyses that examine a relationship with factor variables. Our three topics today are: independent and dependent variables, the t-test, and the chi-square.
7.2.1 Independent and Dependent Variables
When setting hypotheses, we primarily wanted to know whether there was a relationship between certain variables. Inadvertently, we also were arranging our variables in a way that indicated one was the explanation and the other was the outcome.
Using our previous example on sex and fear of crime, we can arrange them so that sex is the independent variable (IV or \(X\)), indicating that it is presumed to have an impact on the level of fear of crime, the dependent variable (DV or \(Y\)), considered to be influenced by \(X\).
We believe that sex (\(X\)) has an influence on level of fear of crime (\(Y\)), and hypothesise, based on previous research, that males will have lower levels of fear of crime than females. We then select a sample, collect our data from that sample, and conduct an appropriate statistical test to find out whether our hypothesis holds.
An important point to remember is that, although the independent variable (IV) is considered to influence the dependent variable (DV), it does not mean the IV causes the DV. We can only arrange these variables in the direction we think is suitable and make statements about whether they are related to or correlated with each other.
This idea of ‘cause’ is referred to as causal inference and is, in itself, a whole area of research, as establishing causal relationships is not an easy task. One approach we have covered and made reference to throughout your data analysis and research methods classes is to use experimental research designs, such as randomised control trials. If you are interested in causal inference, Scott Cunningham’s Causal Inference Mixtape is highly recommended. Nevertheless, for the kinds of analysis we will be doing in this class, it is best to keep in mind that correlation does not mean causation.
7.2.2 Comparing means: the t-test
When assessing the relationship between a binary, categorical variable and a numeric variable, we usually summarise the numeric variable for each category of the categorical variable in order to compare. For example, we are interested in fear of crime and how levels of it vary between sexes. For this, we have two relevant variables in our data frame BCS0708: sex and tcviolent. Let us have a look:
attributes(BCS0708$sex)## $label
## [1] "respondent sex"
##
## $format.stata
## [1] "%8.0g"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## male female
## 1 2# Any missing values?
table(is.na(BCS0708$sex))##
## FALSE
## 11676We can see that the first variable, sex, takes the values of ‘1’ for ‘male’ and ‘2’ for ‘female’. This variable should be classed as a factor, in R speak, so let us recode sex so that it is classed as so:
# As is, 'sex' is classed as 'haven-labelled', which is incorrect, so we change it to its correct class, factor:
BCS0708$sex <- as_factor(BCS0708$sex)
# Double check that it is now a factor:
attributes(BCS0708$sex) # indeed## $levels
## [1] "male" "female"
##
## $class
## [1] "factor"
##
## $label
## [1] "respondent sex"Now we check out our other variable of interest, tcviolent:
attributes(BCS0708$tcviolent)## $label
## [1] "respondent level of worry about being a victim of personal crime (high score = h"
##
## $format.stata
## [1] "%9.0g"class(BCS0708$tcviolent)## [1] "numeric"# Any missing values?
table(is.na(BCS0708$tcviolent)) # Yes, there is!##
## FALSE TRUE
## 8434 3242The variable, tcviolent, represents ‘respondent level of worry about being a victim of personal crime (high score = high worry)’. This is a numeric variable and measures fear of crime.
7.2.2.1 Activity 2: Exploring our data with descriptive statistics
Before conducting further tests, let us do some exploratory data analysis by getting to know our variables of interest. We use the function summarise() to examine the variable sex and use the function n() to obtain frequencies:
# Examining distribution of sex variable
BCS0708 %>% group_by(sex) %>% summarise(n = n())## # A tibble: 2 x 2
## sex n
## * <fct> <int>
## 1 male 5307
## 2 female 6369The output displays 5307 males and 6369 females.
Now for our dependent variable tcviolent: we use the skim() function from the skimr package introduced in Lesson 4:
# We do not use 'summarise()' because this is a numeric variable
skim(BCS0708, tcviolent)| skim_type | skim_variable | n_missing | complete_rate | numeric.mean | numeric.sd | numeric.p0 | numeric.p25 | numeric.p50 | numeric.p75 | numeric.p100 | numeric.hist |
|---|---|---|---|---|---|---|---|---|---|---|---|
| numeric | tcviolent | 3242 | 0.7223364 | 0.0455821 | 1.00436 | -2.35029 | -0.6718318 | -0.116783 | 0.53989 | 3.805476 | ▁▇▅▂▁ |
Then we get to know the data further by checking out the dependent variable, tcviolent, by the independent variable sex. Let us now look at the mean, standard deviation, and variance:
# We tell R to obtain the three descriptive statistics and 'round' the values to two decimal places
# Remember, we must add 'na.rm = TRUE' as we have missing values or else this will display 'NA'
BCS0708 %>% group_by(sex) %>%
summarise(mean_worry = round(mean(tcviolent, na.rm = TRUE),2),
sd_worry = round(sd(tcviolent, na.rm = TRUE),2),
var_worry = round(var(tcviolent, na.rm = TRUE),2))## # A tibble: 2 x 4
## sex mean_worry sd_worry var_worry
## * <fct> <dbl> <dbl> <dbl>
## 1 male -0.27 0.86 0.74
## 2 female 0.33 1.04 1.08The mean for females is higher than that of males, and we have quite high dispersion too, as indicated by the variance. We observe how scores from tcviolent might differ between sexes in the variable sex.
In addition, we can visualise a five-number summary with boxplots (see Lesson 3, section 3.3.3.3):
ggplot(BCS0708, aes (x = tcviolent, group = sex, fill = sex)) +
geom_boxplot() +
coord_flip() +
theme_bw() ## Warning: Removed 3242 rows containing non-finite values (stat_boxplot).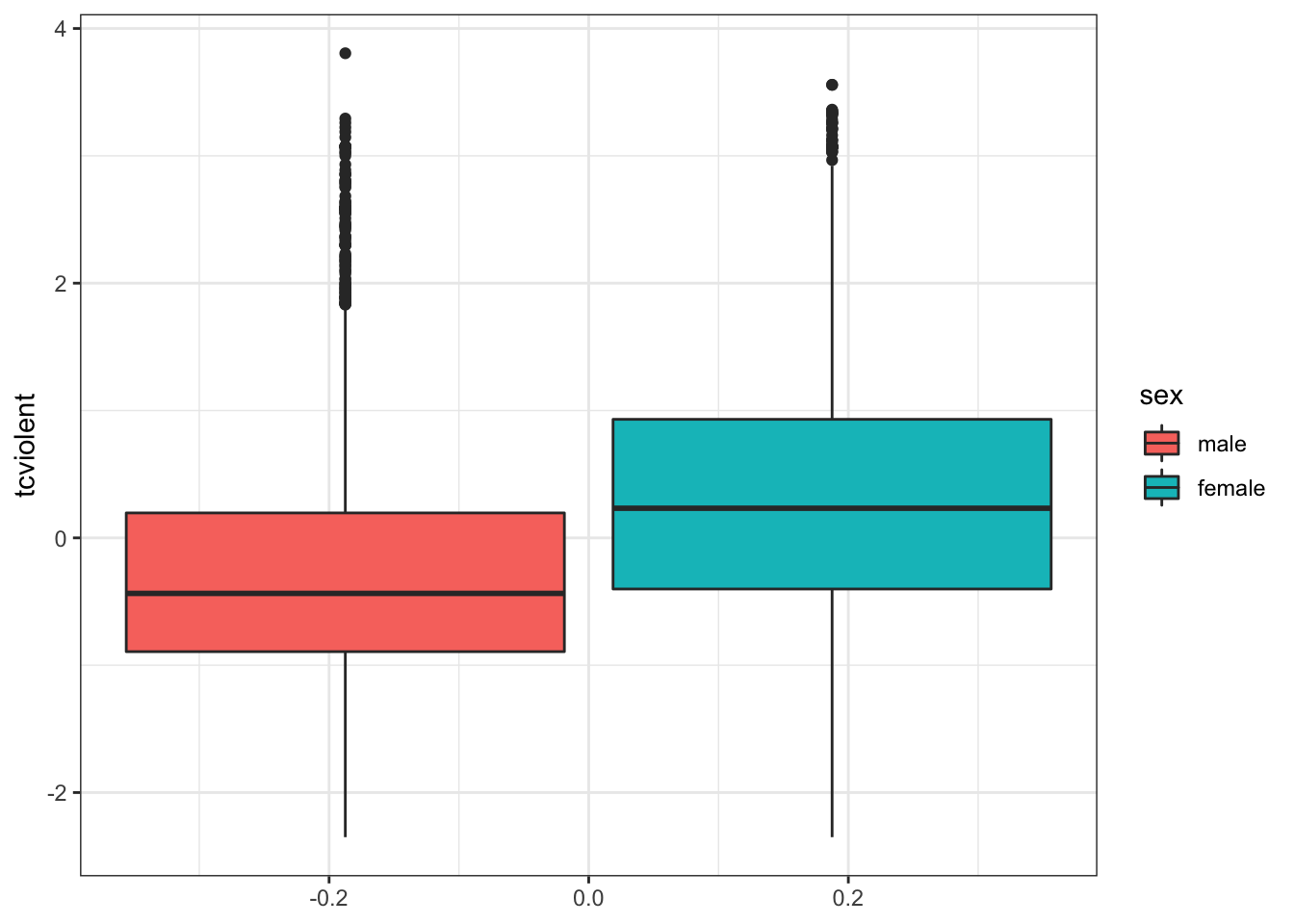
Note that these descriptive statistics are only about our sample; we actually want to make inferences about our population of interest – all males and females in England and Wales. So, we use inferential statistics; our observation of a difference between means prompts us to test whether this difference is an actual difference, or if it is attributed to chance.
Hence, our hypothesis is that, in the population, there is a difference in the mean level of fear of crime for males compared to said levels for females.
Our non-directional hypothesis has to do with our research question of whether there is a difference in the amount of fear of crime between males and females. As one of our variables of interest is binary, categorical and the other, numeric, we test our hypothesis using the t-test, which relies on Student’s t distribution.
7.2.2.2 Student’s t distribution
In previous weeks, we used the standard deviation (SD or \(s\)) of our sample to estimate the standard error (SE or \(\sigma\)). (See Lesson 5, section 5.2.2 .) This approach works reasonably well when applied to large samples. With small samples, however, using the SD as an estimate of the SE is problematic.
The reason is that the SD varies from sample to sample, so this variation in smaller samples makes for more uncertainty. In addition, we are likely not to know the true population values, our parameters. For such a case, William Gosset, Statistician and Head Brewer for Guinness, (see also recommended reading) suggested that we needed to use a different probability distribution, Student’s t distribution.
Gosset had developed this distribution (under his pen name ‘Student’) so that he could make meaningful predictions using small samples of barley instead of large ones – a cost-effective method. A small sample is considered to be less than 60 observations, and definitely 30 or less. (The ambiguity of this is because various textbooks have different ideas on what constitutes a ‘small sample’ but the rule of thumb is n= 30.)
7.2.2.3 Assumptions of the t-test
The t-test makes a number of assumptions, and to use this test, all assumptions should be met:
Two means or proportions will be compared: our independent variable is binary, signifying two groups, and the dependent variable is a numeric variable (or a binary variable for comparision of proportions, but this requires a large sample size).
The sampling method was independent random sampling. We will proceed as if this assumption is met.
Normal distribution is assumed for both populations (from which the two groups come from): because the t-test makes assumptions about the shape of the distribution, it is considered a parametric test. Tests that do not make this assumption about shape are called non-parametric. This assumption, however, can be relaxed if the sample size for both groups are large (and why proportions can be compared).
You may also want to check for outliers by plotting the data. Outliers may distort your results, particularly with smaller samples. All assumptions with the exception of the second one are met. To meet the third assumption, you can check if your data are normally distributed, especially if the sample size(s) is not large, using density plots:
ggplot(BCS0708, aes(x = tcviolent, fill = sex)) +
geom_density(alpha = 0.5) +
theme_bw()## Warning: Removed 3242 rows containing non-finite values (stat_density).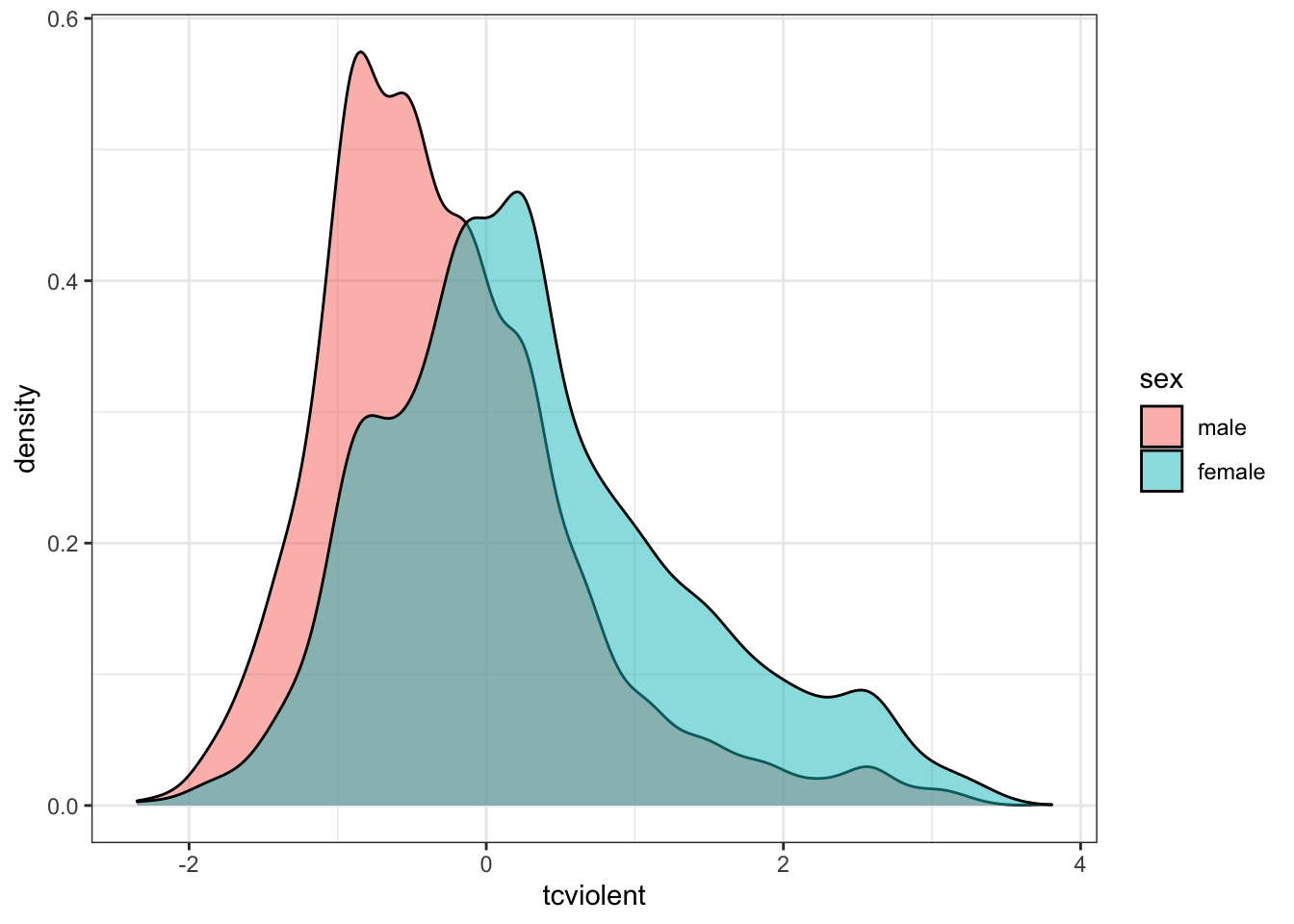
The density plots provide a visual tool for assessing the unimodality – a single, clear peak indicating a most frequent value – and the symmetry of the distribution. For now, let us assume that this is adequate to compute the t-test.
- The variances of both samples are equal to each other. We test for this in the next section.
For an independent sample t-test, however, an additional assumption must be met:
- The two groups must be independent of each other: This assumption of independence would be violated if, for example, one group comprised women and the other group, their partners. If this were the case, the resulting values for both groups would be connected and misleading. If this assumption is violated, we would need the dependent t-test, which will be covered later.
7.2.2.4 Independent Sample t-test
In our example, we would like to know whether there is a difference between the mean score of fear of crime, as embodied in the variable tcviolent, between males and females. Previously, we fulfilled three assumptions for the independent sample t-test or unpaired t-test. This t-test compares two groups that are independent of one another. It suggests that the values for the dependent variable in one group are not reliant on the values for the dependent variable in the other group. In our case, levels of fear of crime for females and males are not related to one another, so the fifth assumption is met.
In addition to our research question which asks whether there is a difference in the amount of fear of crime between males and females, our null and alternative hypotheses are:
\(H_0\): There is no significant difference in fear of crime between males and females.
\(H_A\): There is a significant difference in fear of crime between males and females.
7.2.2.4.1 Activity 3: Testing for equality of variance
We must meet the fouth assumption by conducting the test for equality of variance, also known as Levene’s test. Conducting this specific test is an important step before the t-test. This is an F-test that evaluates the null hypothesis that the variances of the two groups are equal. When we want to compare variances, we conduct this test as the variances may affect how we specify our t-test. If we fail to reject the null hypothesis, then we have met this assumption.
# DV comes first in code, then the IV
var.test(BCS0708$tcviolent ~ BCS0708$sex)##
## F test to compare two variances
##
## data: BCS0708$tcviolent by BCS0708$sex
## F = 0.68886, num df = 3958, denom df = 4474, p-value < 2.2e-16
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 0.6484653 0.7318632
## sample estimates:
## ratio of variances
## 0.6888643The information to focus on in the output are the alternative hypothesis, the F-statistic, and associated p-value. The alternative hypothesis states that the variances are not equal to 1, meaning they are not equal to each other. Likewise, the p-value is very small, so we reject the null hypothesis that the variances are equal to each other. Thus, we have violated this assumption of equal variances, so we must address this.
One way to do so, and is familiar to one of the lesson’s lecture videos, is to use the t.test() function. There, you can specify whether the equality of variance assumption is met. In our case, we must set var.equal to FALSE in the following independent sample t-test as the assumption is violated.
7.2.2.4.2 Activity 4: Conducting an independent sample t-test
It is now time to carry out our t-test. We use the t.test() function, which performs both the one and two sample t-tests on vectors of data. It can also perform paired and independent samples t-tests by modifying the paired= argument. We include our independent and dependent variables, separated by a tilda (~), and set the var.equal argument to FALSE:
# Run the t-test with var.equal option set to false as assumption was violated:
t.test(BCS0708$tcviolent ~ BCS0708$sex, var.equal = FALSE)##
## Welch Two Sample t-test
##
## data: BCS0708$tcviolent by BCS0708$sex
## t = -29.114, df = 8398.3, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.6425300 -0.5614656
## sample estimates:
## mean in group male mean in group female
## -0.2738322 0.3281656# You can save your results in an object, too, to refer back to later:
t_test_results <- t.test(BCS0708$tcviolent ~ BCS0708$sex, var.equal = FALSE)
# Print independent t-test results
t_test_results##
## Welch Two Sample t-test
##
## data: BCS0708$tcviolent by BCS0708$sex
## t = -29.114, df = 8398.3, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## -0.6425300 -0.5614656
## sample estimates:
## mean in group male mean in group female
## -0.2738322 0.3281656From the output, focus on: the means, alternative hypothesis (\(H_A\)), the t-statistic, the p-value, and the 95% confidence interval (CI).
First, the means show that males score an average score of -0.2738322 on this fear of crime measure, while females score an average of 0.3281656 - this is the same output we got from exploring our data previously.
Second, the alternative hypothesis is not equal to 0, which is what we expect if there is no difference between the two groups.
Third, the t-statistic reports -29.1142624 with an associated p-value that is much smaller than our \(\alpha\) = 0.05, so we reject the null hypothesis that the difference in the population is 0. We can say that there is a statistically significant difference between fear of crime for males and females in England and Wales. We can also state that, given the null hypothesis, there is a < .001 chance of observing the difference that we have actually observed (or one more unlikely).
Fourth, the 95% CI allows us to make an estimate of the difference in means in the population. From our sample, we estimate that the difference in fear of crime scores between sexes is somewhere between 0.56 and 0.64 points.
Is this considered a large or small difference? In many cases, interpreting this is challenging because it can be subjective or the scale that was used to measure the variable is not the original, raw version. To help us answer our question of size difference, we will need to include a measure of effect size.
7.2.2.4.3 Activity 5: Considering the effect size- Cohen’s d
We can always look at standardised measures of the effect size. There are a number of them. They aim to give you a sense of how large the difference is by using a standardised metric. The value indicating the strength of relationship is known as the effect size, and simply quantifies the magnitude of difference between two variables.
We will use one of the measures, Cohen’s d, for this example. We can obtain it with the cohen.d() function from the effsize package:
cohen.d(BCS0708$tcviolent ~ BCS0708$sex)##
## Cohen's d
##
## d estimate: -0.6281126 (medium)
## 95 percent confidence interval:
## lower upper
## -0.6719205 -0.5843047Jacob Cohen (inventor of Cohen’s d) suggested a general guideline to interpret this effect size as an absolute value: 0.2 to 0.3 is considered a ‘small’ effect; around 0.5, a ‘medium’ effect; and 0.8 and larger, a ‘large’ effect. The output suggests that the observed difference is a medium effect size.
To communicate the results obtained from our descriptive statistics, the t-test, and Cohen’s d, we could write something like the following:
‘On average, males have a lower score of fear of crime (M=-.27, SD=.86) than females (M= 0.33, SD= 1.04). Using an alpha level of 0.05, this difference was significant (t= -29.11, p <.001) and corresponds to a medium-sized effect (d= -0.63).’
Communicating this way is similar to the way findings are communicated in the ‘Results’ section of academic papers.
7.2.2.5 Dependent Sample t-test
Previously, we went through the assumptions of an independent sample t-test. If we had violated the fifth assumption, we would need to use the dependent sample t-test instead. But, also, we use this t-test when we are actually interested in comparing means of two groups that are related to each other, the dependent sample t-test or paired sample t-test is appropriate. What this means is that the responses are paired together because there is a prior connection between them. For example, the same people form both of our groups, where the first group comprises their test scores before an intervention and the second one comprises their test scores after that intervention. The scores are connected to each other because they belong to the same people.
7.2.2.5.1 Activity 6: Conducting a dependent sample t-test
Let us create a familiar synthetic data of a hypothetical intervention for at-risk youth in Manchester. We have identified 100 at-risk young people and exposed them to an intervention designed to stop them from reoffending. Both before and after the intervention, though, we ask them to take a test that measures their compliance with the law.
set.seed(1999) # Ensuring results are the same for you and me
# Making this sythentic data of at-risk youth
df <- data.frame(subject_id = c(1:100, 1:100), # ID for each young person
prepost = c(rep("pre", 100), rep("post", 100)), # Whether assessed before or after intervention
compliance_score = c(rnorm(100, 30, 10), rnorm(100, 60, 14))) # Test scoresWe now have our data frame called df, which contains a total of 200 observations (our young people) of their scores on the compliance test taken before and after the intervention. This can be seen as two waves of a survey; we compare the behaviours of the young people from Wave 1 to Wave 2 to address the research question: ‘Do the compliance scores of the young people change after our intervention?’ Our non-directional null and alternative hypotheses are as follows:
\(H_0\): There is no significant difference in the compliance scores between Wave 1 (pre-intervention) and Wave 2 (post-intervention).
\(H_A\): There is a significant difference in the compliance scores between Wave 1 (pre-intervention) and Wave 2 (post-intervention).
As responses from both Waves 1 and 2 are required, cases with missing responses from either will be dropped automatically when our analysis is conducted. Assumptions one to three are met, but how about equality of variance?
# DV comes first in code, then the IV
var.test(df$compliance_score ~ df$prepost)##
## F test to compare two variances
##
## data: df$compliance_score by df$prepost
## F = 1.6479, num df = 99, denom df = 99, p-value = 0.01367
## alternative hypothesis: true ratio of variances is not equal to 1
## 95 percent confidence interval:
## 1.108752 2.449111
## sample estimates:
## ratio of variances
## 1.647864The p-value is less than \(\alpha\) = 0.05. This means that we, again, have unequal variances, so we must specify this in the var.equal= argument of the t.test() function. We conduct the dependent sample t-test:
# Use the variables `prepost` indicating whether the answer is from wave 1 (pre-intervention) or wave 2 (post-intervention) and `compliance_score`, the score the young person achieved on the compliance questionnaire.
# Specify TRUE for the `paired` option
t.test(compliance_score ~ prepost, data = df, var.equal= FALSE, paired= TRUE)##
## Paired t-test
##
## data: compliance_score by prepost
## t = 18.075, df = 99, p-value < 2.2e-16
## alternative hypothesis: true difference in means is not equal to 0
## 95 percent confidence interval:
## 27.38580 34.13993
## sample estimates:
## mean of the differences
## 30.76287The results indicate that we can reject the null hypothesis as the p-value is less than \(\alpha\) = 0.05. We conclude that there is a significant difference in compliance scores before and after our intervention, between Wave 1 and Wave 2. The mean difference, 95% of time when repeated samples are taken from the population, will be between 27.39 and 34.14 points. On average, compliance scores were 30.76 points higher than before the intervention. What is the magnitude of this difference?
We, again, use Cohen’s d to find out. As this is a paired t-test, we must conduct it slightly differently than when we did for the independent t-test. We specify the argument paired= TRUE and specify what ID it can use to match our participants in the pre- and post- groups (the variable subject_id); this is done with the Subject() array appended with the | operator:
cohen.d(compliance_score ~ prepost | Subject(subject_id), data = df, paired= TRUE)##
## Cohen's d
##
## d estimate: 2.798971 (large)
## 95 percent confidence interval:
## lower upper
## 2.121816 3.476126The magnitude of the difference between pre and post test compliance scores is considered a large effect (d = 2.799). In addition, 95% of the time, when we draw samples from this population, we would expect the effect size to be between 2.12 and 3.48. Our intervention seems to be associated with increased test scores. But remember: correlation is not causation!
7.2.3 Chi-square
The chi-square statistic is a test of statistical significance for two categorical variables. It tells us how much the observed distribution differs from the one expected under the null hypothesis. It is based on the cross-tabulation (aka crosstabs) or contingency table. These appear as a table that simultaneously shows the frequency distributions of two categorical variables that do not have too many levels or categories.
7.2.3.1 Activity 7: Cross-tabulations
To explore some relationships related to the fear of crime, we return to the BCS data to produce a cross-tabulation of victimisation (bcsvictim) and whether the presence of rubbish is common in the area where the respondent lives (rubbcomm). According to Broken Windows Theory, proposed by James Q. Wilson and George Kelling, we should see a relationship between these two variables.
First, we get to know our variables:
# Seeing what class these variables are
class(BCS0708$bcsvictim)## [1] "haven_labelled" "vctrs_vctr" "double"class(BCS0708$rubbcomm)## [1] "haven_labelled" "vctrs_vctr" "double"# 0-Not victim of crime; 1-Victim of crime
attributes(BCS0708$bcsvictim) ## $label
## [1] "experience of any crime in the previous 12 months"
##
## $format.stata
## [1] "%8.0g"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## not a victim of crime victim of crime
## 0 1# 5-point Likert-scale ranging from 1 (very common) to 4 (not common)
attributes(BCS0708$rubbcomm)## $label
## [1] "in the immediate area how common is litter\\rubbish"
##
## $format.stata
## [1] "%8.0g"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## very common fairly common not very common not at all common
## 1 2 3 4
## not coded
## 5# We can change these variables to factors:
BCS0708$bcsvictim <- as_factor(BCS0708$bcsvictim)
BCS0708$rubbcomm <- as_factor(BCS0708$rubbcomm)Notice that rubbcomm ranges from ‘1’ to ‘4’, from ‘very common’ to ‘not at all common’. It would make sense if the numbers reflected, instead, the order of levels from ‘not at all common’ (‘1’) to ‘very common’ (‘4’) – from less to more. To re-order the categories/ levels, we use the familiar function factor() from Lesson 2:
# We request for R to change the levels so that it goes from 'not at all common' to 'very common' in the 'levels = c()' argument
# As 'rubbcomm' is a factor, we use the 'factor()' function to specify
BCS0708$rubbcomm <- factor(BCS0708$rubbcomm, levels = c("not at all common", "not very common", "fairly common", "very common"))
# Double check that the levels have been reordered:
attributes(BCS0708$rubbcomm) # Indeed## $levels
## [1] "not at all common" "not very common" "fairly common"
## [4] "very common"
##
## $class
## [1] "factor"Now we observe any missing values:
# If you want the frequency distribution with labels, use ‘as_factor ()’
table(as_factor(BCS0708$bcsvictim))##
## not a victim of crime victim of crime
## 9318 2358table(as_factor(BCS0708$rubbcomm))##
## not at all common not very common fairly common very common
## 5463 4154 1244 204# Checking for any missing values using ‘sum ()’ to count number of NA data
sum(is.na(BCS0708$bcsvictim))## [1] 0# 611 are indicated as missing
sum(is.na(BCS0708$rubbcomm))## [1] 611For the DV, rubbcomm, we are missing 611 observations. For our class, keep in mind that all the statistical tests you will learn rely on full cases analysis whereby the tests will exclude observations that have missing values. There are appropriate ways in dealing with missing data but this is beyond the scope of this class.
Although, previously, we learned how to obtain contingency tables with the table() function from base R and with the dplyr package, the best package for crosstabs is gmodels. It allows you to produce cross-tabulations in a format similar to the one used by commercial statistical packages SPSS and SAS. We use the function CrossTable (), then the with() function to identify the data frame at the outset instead of having to include it with each variable (using $).
# Is the package `gmodels` loaded?
# Define the rows in your table (rubbcomm) and then the variable that will define the columns (bcsvictim)
with(BCS0708, CrossTable(as_factor(rubbcomm),
as_factor(bcsvictim), prop.chisq = FALSE, format = c("SPSS")))##
## Cell Contents
## |-------------------------|
## | Count |
## | Row Percent |
## | Column Percent |
## | Total Percent |
## |-------------------------|
##
## Total Observations in Table: 11065
##
## | as_factor(bcsvictim)
## as_factor(rubbcomm) | not a victim of crime | victim of crime | Row Total |
## --------------------|-----------------------|-----------------------|-----------------------|
## not at all common | 4614 | 849 | 5463 |
## | 84.459% | 15.541% | 49.372% |
## | 52.408% | 37.550% | |
## | 41.699% | 7.673% | |
## --------------------|-----------------------|-----------------------|-----------------------|
## not very common | 3173 | 981 | 4154 |
## | 76.384% | 23.616% | 37.542% |
## | 36.040% | 43.388% | |
## | 28.676% | 8.866% | |
## --------------------|-----------------------|-----------------------|-----------------------|
## fairly common | 876 | 368 | 1244 |
## | 70.418% | 29.582% | 11.243% |
## | 9.950% | 16.276% | |
## | 7.917% | 3.326% | |
## --------------------|-----------------------|-----------------------|-----------------------|
## very common | 141 | 63 | 204 |
## | 69.118% | 30.882% | 1.844% |
## | 1.602% | 2.786% | |
## | 1.274% | 0.569% | |
## --------------------|-----------------------|-----------------------|-----------------------|
## Column Total | 8804 | 2261 | 11065 |
## | 79.566% | 20.434% | |
## --------------------|-----------------------|-----------------------|-----------------------|
##
## Cells for the central two columns are the total number of cases in each category, comprising the row percentages, the column percentages, and the total percentages. The cross-tabulation shows that 63 people in the category ‘rubbish is very common’ were victims of a crime; this represents 30.88% of all the people in the ‘rubbish is very common’ category (your row percent), 2.79% of all the people in the ‘victim of a crime’ category (your column percent), and 0.57% of all the people in the sample.
There is quite a lot of proportions that the contingency table will churn out, but you are only interested in the proportions or percentages that allow you to make meaningful comparisons.
If you believe in broken windows theory, you will think of victimisation as the outcome we want to explain (dependent variable or \(Y\)) and rubbish in the area as a possible explanation for the variation in victimisation (independent variable or \(X\)). If so, you will need to request percentages that allow you to make comparisons across rubbcomm for the outcome, bcsvictim.
This is a very important point: often, cross tabulations are interpreted the wrong way because percentages were specified incorrectly. Two rules to help ensure you interpret crosstabs correctly:
If your dependent variable is defining the rows, then you ask for the column percentages
If your dependent variable is defining the columns, then you ask for the row percentages
Also, you make comparisons across percentages in the direction where they do not add up to a hundred percent. For example, 30.88% of people who live in areas where rubbish is very common have been victimised, whereas only 15.54% of people who live in areas where rubbish is not at all common have been victimised in the previous year. To make it easier, we can ask R to only give us the percentages in that we are interested:
# prop.c is column and prop.t is total
with(BCS0708, CrossTable(as_factor(rubbcomm),
as_factor(bcsvictim),
prop.chisq = FALSE, prop.c = FALSE, prop.t = FALSE, format =
c("SPSS")))##
## Cell Contents
## |-------------------------|
## | Count |
## | Row Percent |
## |-------------------------|
##
## Total Observations in Table: 11065
##
## | as_factor(bcsvictim)
## as_factor(rubbcomm) | not a victim of crime | victim of crime | Row Total |
## --------------------|-----------------------|-----------------------|-----------------------|
## not at all common | 4614 | 849 | 5463 |
## | 84.459% | 15.541% | 49.372% |
## --------------------|-----------------------|-----------------------|-----------------------|
## not very common | 3173 | 981 | 4154 |
## | 76.384% | 23.616% | 37.542% |
## --------------------|-----------------------|-----------------------|-----------------------|
## fairly common | 876 | 368 | 1244 |
## | 70.418% | 29.582% | 11.243% |
## --------------------|-----------------------|-----------------------|-----------------------|
## very common | 141 | 63 | 204 |
## | 69.118% | 30.882% | 1.844% |
## --------------------|-----------------------|-----------------------|-----------------------|
## Column Total | 8804 | 2261 | 11065 |
## --------------------|-----------------------|-----------------------|-----------------------|
##
## Now with this output, we only see the row percentages. Marginal frequencies appear as the right column and bottom row. Row marginals show the total number of cases in each row. For example, 204 people perceive rubbish as very common in the area where they are living and 1,244 perceive rubbish as fairly common in their area. Column marginals show the total number of cases in each column: 8,804 non-victims and 2,261 victims.
In the central cells, these are the total number for each combination of categories. For example, for row percentages, 63 people who perceive rubbish as very common in their area and who are a victim of a crime represent 30.88% of all people who have reported that rubbish is common (63 out of 204). For column percentages (from first crosstab output), 63 people who live in areas where rubbish is very common and are victims represent 2.79% of all people who were victims of crime (63 out of 2,261).
7.2.3.2 Acivity 8: Comparing categorical variables with chi-square test
We now have an understanding of crosstabs so that we can interpret the chi-square statistic. Our null and alternative hypotheses are as follows:
\(H_0\): Victimisation and how common rubbish is in the area are not related to each other. (They are considered independent of each other.)
\(H_A\): Victimisation and how common rubbish is in the area are significantly related to each other. (They are considered dependent on each other.)
We use the chi-square test because it compares these expected frequencies with the ones we actually observe in each of the cells; then averages the differences across the cells; and produces a standardised value, χ\(^2\) (the chi-square statistic).
We then would observe the chi-square distribution to see how probable or improbable this value is. But, in practice, the p-value helps us ascertain this more quickly.
Crosstabs also can show the different frequencies: expected frequencies are the number of cases you would expect to see in each cell within a contingency table if there was no relationship between the two variables – if the null hypothesis were true. Observed frequencies are the cases that we actually see in our sample. We use the CrossTable () function again, specifying that we would like to see expected frequencies by setting expected = TRUE:
with(BCS0708, CrossTable(as_factor(rubbcomm),
as_factor(bcsvictim),
expected = TRUE, prop.c = FALSE, prop.t = FALSE, format =
c("SPSS") ))##
## Cell Contents
## |-------------------------|
## | Count |
## | Expected Values |
## | Chi-square contribution |
## | Row Percent |
## |-------------------------|
##
## Total Observations in Table: 11065
##
## | as_factor(bcsvictim)
## as_factor(rubbcomm) | not a victim of crime | victim of crime | Row Total |
## --------------------|-----------------------|-----------------------|-----------------------|
## not at all common | 4614 | 849 | 5463 |
## | 4346.701 | 1116.299 | |
## | 16.437 | 64.005 | |
## | 84.459% | 15.541% | 49.372% |
## --------------------|-----------------------|-----------------------|-----------------------|
## not very common | 3173 | 981 | 4154 |
## | 3305.180 | 848.820 | |
## | 5.286 | 20.583 | |
## | 76.384% | 23.616% | 37.542% |
## --------------------|-----------------------|-----------------------|-----------------------|
## fairly common | 876 | 368 | 1244 |
## | 989.804 | 254.196 | |
## | 13.085 | 50.950 | |
## | 70.418% | 29.582% | 11.243% |
## --------------------|-----------------------|-----------------------|-----------------------|
## very common | 141 | 63 | 204 |
## | 162.315 | 41.685 | |
## | 2.799 | 10.899 | |
## | 69.118% | 30.882% | 1.844% |
## --------------------|-----------------------|-----------------------|-----------------------|
## Column Total | 8804 | 2261 | 11065 |
## --------------------|-----------------------|-----------------------|-----------------------|
##
##
## Statistics for All Table Factors
##
##
## Pearson's Chi-squared test
## ------------------------------------------------------------
## Chi^2 = 184.0443 d.f. = 3 p = 1.180409e-39
##
##
##
## Minimum expected frequency: 41.68495The output shows that, for example, 63 people lived in areas where rubbish was very common and experienced victimisation in the past year. Under the null hypothesis of no relationship, however, we should have expected 41.69 people (the expected value). Thus, more people are in this cell than we would expect under the null hypothesis.
The chi-square value is 184.04, with 3 degrees of freedom (df). The df is obtained by the number of rows minus one, then multiplied by the number of columns minus one: (4 − 1)*(2 − 1).
The p-value associated with this particular value is nearly zero (p = 1.180e-39). This value is considerably lower than \(\alpha\) = 0.05. We conclude that there is a significant relationship between victimisation and the presence of rubbish. We reject the null hypothesis.
If you do not want to use CrossTable(), you can use chisq.test() to give you only the chi-square value:
chisq.test(BCS0708$rubbcomm, BCS0708$bcsvictim)##
## Pearson's Chi-squared test
##
## data: BCS0708$rubbcomm and BCS0708$bcsvictim
## X-squared = 184.04, df = 3, p-value < 2.2e-167.2.3.3 Fisher’s exact test
For the chi-square to work though, it needs to have a sufficient number of cases in each cell. Notice that R was telling us that the minimum expected frequency is 41.68. One rule of thumb is that all expected cell counts should be above 5. If we do have a small number in the cells, one alternative is to use Fisher’s exact test:
fisher.test(BCS0708$rubbcomm, BCS0708$bcsvictim)# If you get an error message about increasing the size of your workspace, do so with this code:
fisher.test(BCS0708$rubbcomm, BCS0708$bcsvictim, workspace = 2e+07, hybrid = TRUE)##
## Fisher's Exact Test for Count Data hybrid using asym.chisq. iff
## (exp=5, perc=80, Emin=1)
##
## data: BCS0708$rubbcomm and BCS0708$bcsvictim
## p-value < 2.2e-16
## alternative hypothesis: two.sidedWe did not need this test for our example, but we use it to illustrate how to use Fisher’s Exact Test when counts in a cell are low (less than five). The p-value from Fisher’s exact test is still smaller than \(\alpha\) = 0.05, so we reach the same conclusion that the relationship observed can be generalised to the population.
In addition, the chi-square statistic only tells us whether there is a relationship between two variables; it says nothing about the strength of relationship or exactly what differences between observed and expected frequencies are driving the results. We will need to conduct further analyses to address these.
7.2.3.4 Effect size measures related to chi-square
Now that we can generalise to the population, we want to know the magnitude of the difference or the strength of the relationship. We will look at a few ways to talk about this: one, for differences between the observed and expected frequencies; second, for relationships between an ordinal variable and a binary variable; and third, between two binary variables.
7.2.3.4.1 Activity 9: Residuals
We had observed that there were differences between the observed and expected frequencies. This is called a residual. Some differences seem larger than others. For example, there were about 21 more people that lived in areas where rubbish was very common and they experienced more victimisation than what was expected under the null hypothesis. When you see large differences, it is unsurprising to also expect that the cell in question may be playing a particularly strong role in driving the relationship between rubbish and victimisation.
We are not sure, though, of what is considered a large residual. A statistic that helps address this is the adjusted standardised residuals, which behaves like a z-score. Residuals indicate the difference between the expected and observed frequencies on a standardised scale. When the null hypothesis is true, there is only about a 5% chance that any particular standardised residual exceeds 2 in absolute value.
Whenever you see differences that are greater than the absolute value of 2, the difference between expected and observed frequencies in that particular cell is significant and is driving the results of your chi-square test. Absolute values above 3 are considered convincing evidence of a true effect in that cell:
# Include argument ‘asresid= TRUE’ to include adjusted standardised residuals
with(BCS0708, CrossTable(as_factor(rubbcomm), as_factor(bcsvictim), expected = TRUE,
prop.chisq = FALSE, prop.c = FALSE, prop.t = FALSE, asresid =
TRUE, format = c("SPSS") ))##
## Cell Contents
## |-------------------------|
## | Count |
## | Expected Values |
## | Row Percent |
## | Adj Std Resid |
## |-------------------------|
##
## Total Observations in Table: 11065
##
## | as_factor(bcsvictim)
## as_factor(rubbcomm) | not a victim of crime | victim of crime | Row Total |
## --------------------|-----------------------|-----------------------|-----------------------|
## not at all common | 4614 | 849 | 5463 |
## | 4346.701 | 1116.299 | |
## | 84.459% | 15.541% | 49.372% |
## | 12.605 | -12.605 | |
## --------------------|-----------------------|-----------------------|-----------------------|
## not very common | 3173 | 981 | 4154 |
## | 3305.180 | 848.820 | |
## | 76.384% | 23.616% | 37.542% |
## | -6.436 | 6.436 | |
## --------------------|-----------------------|-----------------------|-----------------------|
## fairly common | 876 | 368 | 1244 |
## | 989.804 | 254.196 | |
## | 70.418% | 29.582% | 11.243% |
## | -8.494 | 8.494 | |
## --------------------|-----------------------|-----------------------|-----------------------|
## very common | 141 | 63 | 204 |
## | 162.315 | 41.685 | |
## | 69.118% | 30.882% | 1.844% |
## | -3.736 | 3.736 | |
## --------------------|-----------------------|-----------------------|-----------------------|
## Column Total | 8804 | 2261 | 11065 |
## --------------------|-----------------------|-----------------------|-----------------------|
##
##
## Statistics for All Table Factors
##
##
## Pearson's Chi-squared test
## ------------------------------------------------------------
## Chi^2 = 184.0443 d.f. = 3 p = 1.180409e-39
##
##
##
## Minimum expected frequency: 41.68495The column representing the outcome of interest (victimisation present), shows the adjusted standardised residual is -12.61 for the ‘not at all common’ category. That is the largest residual for the DV. The expected frequency under the null hypothesis in this cell is much higher than that of the observed.
7.2.3.4.2 Activity 10: Goodman-Kruskal’s Gamma
The residuals suggest that the difference is not trivial. One of the tests discussed in the required reading as a test for effect size is Goodman-Kruskal’s Gamma. Gamma is a measure of the strength of the relationship between either two ordinal variables or, in this case, between an ordinal variable and a binary variable.
We first install and load the package vcdExtra and create an object, mytable.2:
# Install 'vcdExtra' then load it
library(vcdExtra)## Loading required package: vcd## Loading required package: grid## Loading required package: gnm##
## Attaching package: 'vcdExtra'## The following object is masked from 'package:dplyr':
##
## summarise# We create a new object in tabular form because the function we use to compute Gamma is table()
mytable.2 <- table(BCS0708$bcsvictim, BCS0708$rubbcomm)
# Print the content of this object to see that it is simply the crosstab
print(mytable.2)##
## not at all common not very common fairly common
## not a victim of crime 4614 3173 876
## victim of crime 849 981 368
##
## very common
## not a victim of crime 141
## victim of crime 63We then use the GKgamma() function from the vcdExtra package to compute Gamma:
# Between the parenthesis, you need to include the object that contains the data
GKgamma(mytable.2) ## gamma : 0.266
## std. error : 0.019
## CI : 0.229 0.302Gamma can take on values ranging from −1 to +1, where: 0 indicates no relationship at all; a negative value indicates a negative relationship; and a positive value, a positive relationship. The closer the value is to either −1 or +1, the stronger the relationship is between variables.
De Vaus (2002) provides the following rules of thumb for interpreting effect size strength for Gamma: up to 0.10 (trivial), 0.10 to 0.29 (low to moderate), 0.30 to 0.49 (moderate to substantial), 0.50 to 0.69 (substantial to very strong), 0.70 to 0.89 (very strong), 0.9 and above (near perfect).
Our output shows that the effect size is positive and low to moderate (Gamma = 0.266): this suggests that the higher levels of rubbcomm are associated with the higher values of bcsvictim. We see, however, that the percentage of people that experience victimisation is almost the same for those who live in areas where rubbish is fairly common and for those who live in areas where it is very common. That is, once we reach a certain level of rubbish, the risk of victimisation does not go much higher. In situations like this, Gamma is likely underestimating the strength of the relationship.
7.2.3.4.3 Activity 11: Odds ratios
To estimate the effect size between two binary variables are odds ratios (ORs). If you have knowledge of betting, you may already know a bit about odds. For this example, we are interested in the relationship between victimisation (bcsvictim) and living in a rural or urban area (rural2):
# Getting to know our data
attributes(BCS0708$rural2)## $label
## [1] "type of area 2004: urban/rural"
##
## $format.stata
## [1] "%8.0g"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## urban rural
## 1 2# Change into a factor
BCS0708$rural2 <- as_factor(BCS0708$rural2)
# We generate crosstabs and conduct the chi-square analysis
with(BCS0708, CrossTable(rural2, bcsvictim, prop.c = FALSE, prop.t = FALSE, expected = TRUE, format = c("SPSS")))##
## Cell Contents
## |-------------------------|
## | Count |
## | Expected Values |
## | Chi-square contribution |
## | Row Percent |
## |-------------------------|
##
## Total Observations in Table: 11676
##
## | bcsvictim
## rural2 | not a victim of crime | victim of crime | Row Total |
## -------------|-----------------------|-----------------------|-----------------------|
## urban | 6757 | 1945 | 8702 |
## | 6944.607 | 1757.393 | |
## | 5.068 | 20.028 | |
## | 77.649% | 22.351% | 74.529% |
## -------------|-----------------------|-----------------------|-----------------------|
## rural | 2561 | 413 | 2974 |
## | 2373.393 | 600.607 | |
## | 14.830 | 58.602 | |
## | 86.113% | 13.887% | 25.471% |
## -------------|-----------------------|-----------------------|-----------------------|
## Column Total | 9318 | 2358 | 11676 |
## -------------|-----------------------|-----------------------|-----------------------|
##
##
## Statistics for All Table Factors
##
##
## Pearson's Chi-squared test
## ------------------------------------------------------------
## Chi^2 = 98.52709 d.f. = 1 p = 3.206093e-23
##
## Pearson's Chi-squared test with Yates' continuity correction
## ------------------------------------------------------------
## Chi^2 = 98.00261 d.f. = 1 p = 4.178318e-23
##
##
## Minimum expected frequency: 600.6074Of those living in urban areas (n= 8,702), 22% reported being a victim of crime in the previous year compared to 14% of those living in rural areas (n = 2,974). The chi-square has a p-value of < 0.001, suggesting a statistically significant relationship between living in urban areas and crime victimisation. But, of course, how large is this relationship? We use the OR to find out.
Before we do so, we need to match the levels of our variables to this type of cross-tabulation:

Figure 7.1 2x2 table to emulate
ORs are commonly used in Public Health, and were introduced in criminology in 1992 by David Hawkins and Richard Catalano. Now, they are used frequently in studies involving the risk factor prevention paradigm, a major component of Developmental and Life Course Criminology.
To compute ORs, they require the variables to correspond to a 2x2 table whereby the independent variable is considered the ‘risk factor’ and the dependent variable is the ‘outcome’. Presence of outcome and risk factor intersect (‘Yes’) at the left hand corner. To ensure our variables correspond to this 2x2 table, we first have a look at their level ordering:
print(levels(BCS0708$bcsvictim))## [1] "not a victim of crime" "victim of crime"print(levels(BCS0708$rural2))## [1] "urban" "rural"We will need to reverse the ordering of the levels in the variable bcsvictim so that ‘victim of crime’ appears as the first level like urban in the variable rural2:
# We recommend that you make a duplicate variable with a different name and the changes, so the original remains (sometimes we do not follow our own advice)
BCS0708$bcsvictimR <- factor(BCS0708$bcsvictim, levels= c("victim of crime", "not a victim of crime"))
print(levels(BCS0708$bcsvictimR))## [1] "victim of crime" "not a victim of crime"# Just double-checking:
table(BCS0708$bcsvictimR)##
## victim of crime not a victim of crime
## 2358 9318table(BCS0708$bcsvictim)##
## not a victim of crime victim of crime
## 9318 2358We can now rerun the previous cross tabulation but with the victim variable bcsvictimR to verify that it resembles that 2x2 table:
with(BCS0708, CrossTable(rural2, bcsvictimR, prop.c = FALSE, prop.t = FALSE, expected = TRUE, format = c("SPSS")))##
## Cell Contents
## |-------------------------|
## | Count |
## | Expected Values |
## | Chi-square contribution |
## | Row Percent |
## |-------------------------|
##
## Total Observations in Table: 11676
##
## | bcsvictimR
## rural2 | victim of crime | not a victim of crime | Row Total |
## -------------|-----------------------|-----------------------|-----------------------|
## urban | 1945 | 6757 | 8702 |
## | 1757.393 | 6944.607 | |
## | 20.028 | 5.068 | |
## | 22.351% | 77.649% | 74.529% |
## -------------|-----------------------|-----------------------|-----------------------|
## rural | 413 | 2561 | 2974 |
## | 600.607 | 2373.393 | |
## | 58.602 | 14.830 | |
## | 13.887% | 86.113% | 25.471% |
## -------------|-----------------------|-----------------------|-----------------------|
## Column Total | 2358 | 9318 | 11676 |
## -------------|-----------------------|-----------------------|-----------------------|
##
##
## Statistics for All Table Factors
##
##
## Pearson's Chi-squared test
## ------------------------------------------------------------
## Chi^2 = 98.52709 d.f. = 1 p = 3.206093e-23
##
## Pearson's Chi-squared test with Yates' continuity correction
## ------------------------------------------------------------
## Chi^2 = 98.00261 d.f. = 1 p = 4.178318e-23
##
##
## Minimum expected frequency: 600.6074ORs are about odds: it is the ratio of two odds – the odds of having the outcome for when the ‘risk factor’ is present and when it is not. For example, the odds of victimisation for urban dwellers is calculated as the number of victimised urban dwellers (1,945) divided by the number of non-victimised urban dwellers (6,757). Therefore, there are 0.2878496 victimised urban dwellers for every non-victimised urban dweller. The odds of victimisation for rural dwellers is calculated as the number of victimised rural dwellers (413) divided by the number of non-victimised rural dwellers (2,561). Thus, there are 0.1612651 victimised rural dwellers for every non-victimised rural dweller.
The OR of victimisation for urban dwellers to rural residents is 1.78 (0.2878496/ 0.1612651). This means that the odds of victimisation are 1.78 times higher for urban dwellers than it is for those in rural areas.
We use R to obtain the OR directly with the vcd package (it may already be loaded because sometimes it accompanies the package vcdExtra):
library(vcd)
mytable.3<-table(BCS0708$rural2, BCS0708$bcsvictimR)
# This produces the OR for the table data in the object called 'mytable.3'
# `stratum` option clarifies your data are not stratified
#`log=FALSE` requests an ordinary OR
oddsratio(mytable.3, stratum = NULL, log = FALSE) ## odds ratios for and
##
## [1] 1.784947Do keep in mind that ORs cannot take on negative values. If the OR is greater than 1, that means that the presence of the risk factor increases the chances of the outcome relative to the absence of that risk factor.
If the OR were between ‘0’and ’1’, that would mean the opposite: the presence of the ‘risk factor’ reduces the chances of the outome relative to the absence of said factor. A value of ‘1’ means that there is no relationship between the two variables – the odds are the same for both groups.
As the OR is about odds, you cannot state that urban dwellers are 1.78 more likely to be victimised. All you can state with an OR is that the odds of being victimised are 1.78 times higher for urban dwellers than for residents in rural areas. Odds and probabilities are different things.
If you are still uncertain about these concepts, and it is normal to feel that way, have a look at this video.
Last, these values must be interpreted carefully. You will often see media reports announcing things like ‘chocolate consumption will double your risk of some \(*insert~ terrible~ disease*\)’. What that means is that the percentage of cases of individuals that take chocolate (the ‘risk factor’) and present the outcome is twice as large as those that do not take chocolate but present the outcome. Yet the probabilities could be very low to start with, so such proclamations can be very misleading (see Figure 7.2).

Figure 7.2 Increased risk
7.3 SUMMARY
We learned a few inferential statistical analyses to examine relationships with categorical variables, known as factors in R. These variables, in today’s analyses, were arranged as independent variables or dependent variables. When analysing a relationship between a categorical and a numeric variable, the t-test was used. We learned to conduct independent sample and dependent sample t-tests.
Before we performed the former t-test, a parametric test, we conducted the test for equality of variance. We also learned about effect size with Cohen’s d. In the latter section, we learned to conduct a chi-square test, a test of statistical significance between two categorical variables. This involved contingency tables or cross tabulations (crosstabs).
The chi-square statistic contrasts expected and observed frequencies in the crosstab. When counts in any one cell is lower than five, Fisher’s Exact Test is used instead. To obtain effect sizes related to the chi-square, we learned to use the adjusted standardised residuals to identify which contrast of frequencies are driving the observed results. We, too, learned about effect size with Gamma and Odds Ratios.
Homework time!