Chapter 3 Data Visualization
Layers and Graphs
Learning Outcomes:
- Understand what the layered approach to Grammar of Graphics and its corresponding package
ggplot2are - Learn how to use
ggplot2to create different visualizations
Today’s Learning Tools:
Total number of activities: 12
Data:
- Official crime data from England and Wales
Packages:
ggplot2ggthemesreadrhere
Functions introduced (and packages to which they belong)
aes(): Mapping aesthetics to variables (ggplot2)as.factor(): Convert to factor, including specifying levels (base R)facet_wrap(): Facet graphics by one or more variables (ggplot2)geom_histogram(): Geometry layer for histograms (ggplot2)geom_line(): Geometry layer for line charts (ggplot2)geom_point(): Geometry layer for scatterplots (ggplot2)ggplot(): Initialize a ggplot graphic, i.e., specify data, aesthetics (ggplot2)labs(): Specify labels for ggplot object, e.g., title, caption (ggplot2)range(): Compute the minimum and maximum values (base R)read_csv(): Read in comma separated values file (readr)scale_color_brewer(): Default color scheme options (ggplot2)scale_color_viridis_d(): Colour-blind-considerate palettes fromviridispackage (ggplot2)theme(): Customise ggplot graphics (ggplot2)theme_economist (): Changes the graphic to resemble ones found in The Economist (ggthemes)theme_minimal(): Default minimalist theme forggplotgraphics (ggplot2)
3.1 Grammar of Graphics
Today we learn the basics of data visualization in R using a package called ggplot2 within the tidyverse, one of the most popular packages for making high-quality, reproducible graphics. The framework on which ggplot2 is based derives from Hadley Wickham’s (2010) A Layered Grammar of Graphics.
Wickham advances the work of Grammar of Graphics by proposing a layered approach to describe and build graphics in a structured manner. Layers, according to Wickham, are used to describe the basic features that underlie any graphic or visualization. Every layer comprises five parts: data, aesthetics, statistical transformation (stat), geometric object (geom), and position adjustment (position).
The three primary ones we focus on to ease you into this, however, are (1) the data, (2) the aesthetics, and (3) the geometric objects:
Data: usually the data frame with tidy rows and columns.
Aesthetics: the visual characteristics that represent the data, or variables. At its simplest, these could be an x- and y-axis, and can extend to other aesthetics like colour, size, and shape, which are mapped to variables.
Geometric objects: also known as ‘geoms’ and represent the data points in the visualization, such as dots or lines.

Figure 3.1 Visualize Table 3
Figure 3.2 Using the Grammar of Graphics approach to convert elements of Table 3 into its visual components
Figure 3.3 Integrating those visual parts of Table 3 into a graphic
Why is this important? Visualizing your data helps you to have a better understanding of them before moving on to more advanced and complex analyses. Numbers themselves can be deceptive and complicated, so by visualizing them, you can identify any patterns or anomalies.
3.1.1 Activity 1: Getting Ready
Before we ‘layer up’, let us do the following:
Open up your existing
Rproject like you had learned last weekLoad the
ggplot2andreadrpackages using thelibrary()function. If you have not already installed these packages, you will need to do so first, using theinstall.packages()function. If you are unclear about the difference between these two functions, see 1.3.3 in Lesson 1 of this online tutorial site or ask now!Download the first two datasets (gmp_2017.csv and gmp_monthly_2017.csv) from Blackboard, in the subfolder ‘Data for this week’ in the Week 3 learning materials. The datasets contain crime data from Greater Manchester, England. Load these two datasets using the
read_csv()function into two separate data frames. Respectively name the data framesburglary_dfandmonthly_dfby using the<-assignment operator.
Make sure the datasets are saved in the sub-folder called ‘Datasets’ that you created last week inside your project directory/ folder. If this is the case, we can use the here() function to tell R where exactly to locate the datasets. (See lecture short 3.1 ‘The R Prep routine’ on Blackboard.)
Create first data frame object, burglary_df and load into it the ‘gmp_2017.csv’ data file:
# gmp_2017.csv
burglary_df <- read_csv(here("Datasets", "gmp_2017.csv"))Now your turn to make the second data frame. Create the second data frame, monthly_df and load into it the ‘gmp_monthly_2017.csv’ data file.
You should have two data frames in your environment now. How many observations (rows) and variables (columns) are in burglary_df? How about in monthly_df?
3.2 ggplot2
This week we will be learning how to use R to create various exciting data visualizations. You may remember some of the key principles of data visualizations from last semester: graphics should be truthful,functional, beautiful, insightful, and enlightening. Also, accessible!
Here is a recent powerful visualization from The New York Times about deaths from COVID-19 in the USA (Figure 3.4): https://twitter.com/beccapfoley/status/1363338950518206472

Figure 3.4 NYT visualization of COVID-19 deaths in USA
R has amazing data visualization qualities. It is increasingly used by professionals and academics to create graphics that embody those principles of data visualization.
For example, read this article about how the BBC uses R to create their graphics: How the BBC Visual and Data Journalism team works with graphics in R (See Figure 3.5)
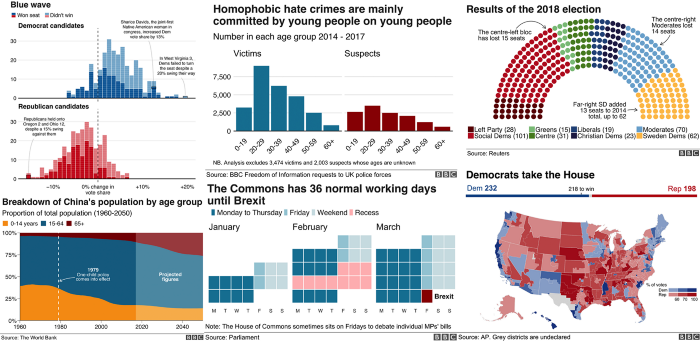
Figure 3.5 How the BBC Visual and Data Journalism team works with graphics in R
As you learn to create graphs in ggplot2, you will see that the code reflects building these graphs as layers. This will take getting used to if you are only familiar with building graphs from a template in Excel. You can also reuse chunks of code to create different kinds of graphics or identical ones in other datasets.
Today we focus on the ggplot2 package to learn our three substantive topics: layers, graphs for categorical data, and graphs for numeric data.
3.2.0.1 Activity 2: Getting to Know New Data
Before we dive into those topics, we need to get into the habit of getting to know our data. Below is a brief ‘data dictionary’ of the variables from both of our data:
A. burglary_df has nine variables:
- LSOAcode: LSOA stands for Lower Super Output Area, and is a statistical unit of geography. It represents neighbourhoods that each contain 300-400 households. Essentially, LSOA means neighbourhood.
- burglary_count: the number of burglaries in each LSOA in 2017
- LAname: the name of the Local Authority into which the LSOA falls
- IMD score: the IMD refers to the Index of Multiple Deprivation. This measure combines seven domains of deprivation into one index: (1) income, (2) employment, (3) education, (4) health, (5) crime, (6) barriers to housing or services, and (7) living environment. It is the score that a particular LSOA has on this measure. You can read more about the measure here: IMD infographic
- IMDrank: another version of the IMD except it ranks all 32,844 LSOAs from highest to lowest deprivation.
- IMDdeci: indicates in what decile of deprivation the LSOA falls.
- incscore: score for income deprivation; this is one of the seven indicators comprising the IMD. Measures the proportion of the population experiencing deprivation relating to low income.
- LSOAname: the name of that particular LSOAs
- pop: the population size of LSOAs
B. monthly_df has three variables:
- Month: month of the year whereby 1 = January, 2 = February… and 12 = December
- crime_type: type of crime (for police.uk categories, see: download police.uk data categories vs home office offence codes)
- n: number of each type of crime for each month in 2017
Have a look at both datasets. Let us use the function View() first. What do you think are the levels of measurement for each variable? Make a note of this.
Now use the the function class() to look at how R treats each variable for each dataset. How does this match with what you think is the level of measurement for each variable? Keep this in mind!
Notice that although monthly_df has only several variables, there is a lot of information in this data frame. There are counts for various different crimes for each month of the year. Because of this, the data are in long format. This is a useful and typical format for longitudinal data because our time variable (i.e., months) is contained in one variable. This will make it easier to create graphics showing change over time.
In addition, when you read a good quantitative research paper, its methods section will state the number of cases analysed with ‘n =’, whereby ‘n’ represents ‘number of cases’. This is known as sample size. For example, if the sample size of a study is two-hundred, the methods section would state it as ‘n= 200’.
In your group google doc, type out the following: the number of observations for each data frame. Type out these values following ‘n =’. In addition, state what you think the unit of analysis is in each data frame.
3.3 Today’s 3
Now that we have gotten to know our data, onto our three main topics: layers, graphs for nominal and ordinal data, and graphs for interval and ratio data.
3.3.1 Layers
Layers often relate to one another and have similar features. For example, they may share the same underlying data on which they are built. An example is this scatterplot overlayed with a smoothed regression line to describe the relationship between two variables:
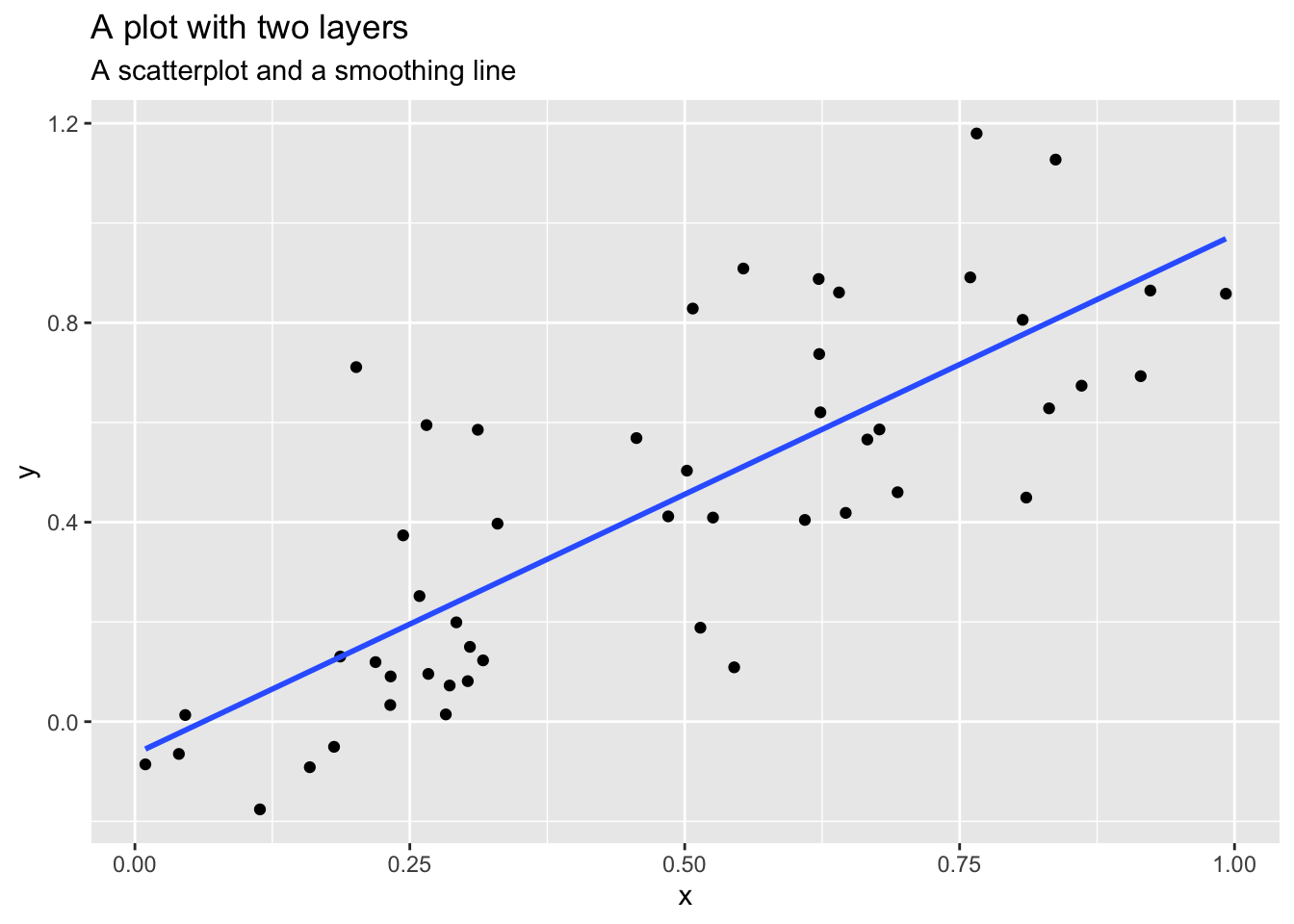
Figure 3.6 A graphic with two layers
From: https://cfss.uchicago.edu/notes/grammar-of-graphics/
One layer is the scatterplot itself and it contains the necessary components (e.g., data, aesthetics, and geom). The second layer is the smoothing line. Another example of multiple layers is this one that uses two different but related datasets in one graphic:
Figure 3.7 Different data sets and aesthetics defined by layer
From: http://applied-r.com/building-layered-plots/
The advantage of the layered approach is its ease for the user and the developer of these statistical graphics. As a user, you can repeatedly update a graphic, changing one feature at a time instead of having to work with the overall graphic; as a developer, you can add more components to your graphic while being able to use what you have already. The idea is that you can tweak your graphic by component or layer while leaving the rest of your graphic intact. This is in constrast to changing the entire graphic just to tweak a small detail.
To understand a layer and how it is generated in ggplot2, we begin with a scatterplot. This is a graph that shows the relationship between two continuous variables – in other words, between two numeric variables.
For example, we may be interested to find out whether there is a relationship between area-level income deprivation and burglaries. Are areas with higher income deprivation scores burgled more? Perhaps there is less money to spend on security systems, so there is easier access to homes in these areas. Or is it areas with lower income deprivation scores that are burgled more? Maybe because these areas are wealthier so there are more valuable goods to take. To visualize this relationship, we build a scatterplot using the layered approach.
3.3.1.1 Activity 3: Using ggplot2 to create a scatterplot
Our research question, therefore, is: What is the relationship between income and burglary counts?
Following the grammar of graphics layered approach, let us first specify the data component. To do this, we take the ggplot() function, and inside it, we put our data frame object, which contains our data. To let the function know this is the data, we can also write data = before it:
# If there is an error about function missing, has the package ggplot2 been installed and loaded?
ggplot(data = burglary_df)
The Plots window will appear and will be blank, like what you see above. We have told R what data we want to plot, but we have yet to specify what variables we want across our x and y axes, or other fields. To do this, we will need aesthetics, the second component of the layer.
Recall that aesthetics are about mapping the visual properties. As our research question is about the relationship between income (incscore) and burglary count (burglary_count), we will map these variables to the x and y axes. We specify the aesthetics inside the aes() function (i.e.,aesthetics), indicating which variable we want on the x axis (x =) and which one on the y axis (y =).
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count))
You will now see an update in the Plots window! It shows the axis and the axes labels. R now knows that we want to plot the income variable on our x axis and the burglary count variable on the y. The labels are applied automatically, but you can change these, which we will soon learn.
Let us learn how to finally put our data on the plot. To do this, we must assign a geometry.
This last component is the geometric object, and is what also makes the layer in R code. It has numerous functions, each beginning with the argument geom_. To create a scatterplot, we use the function geom_point():
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count)) +
geom_point()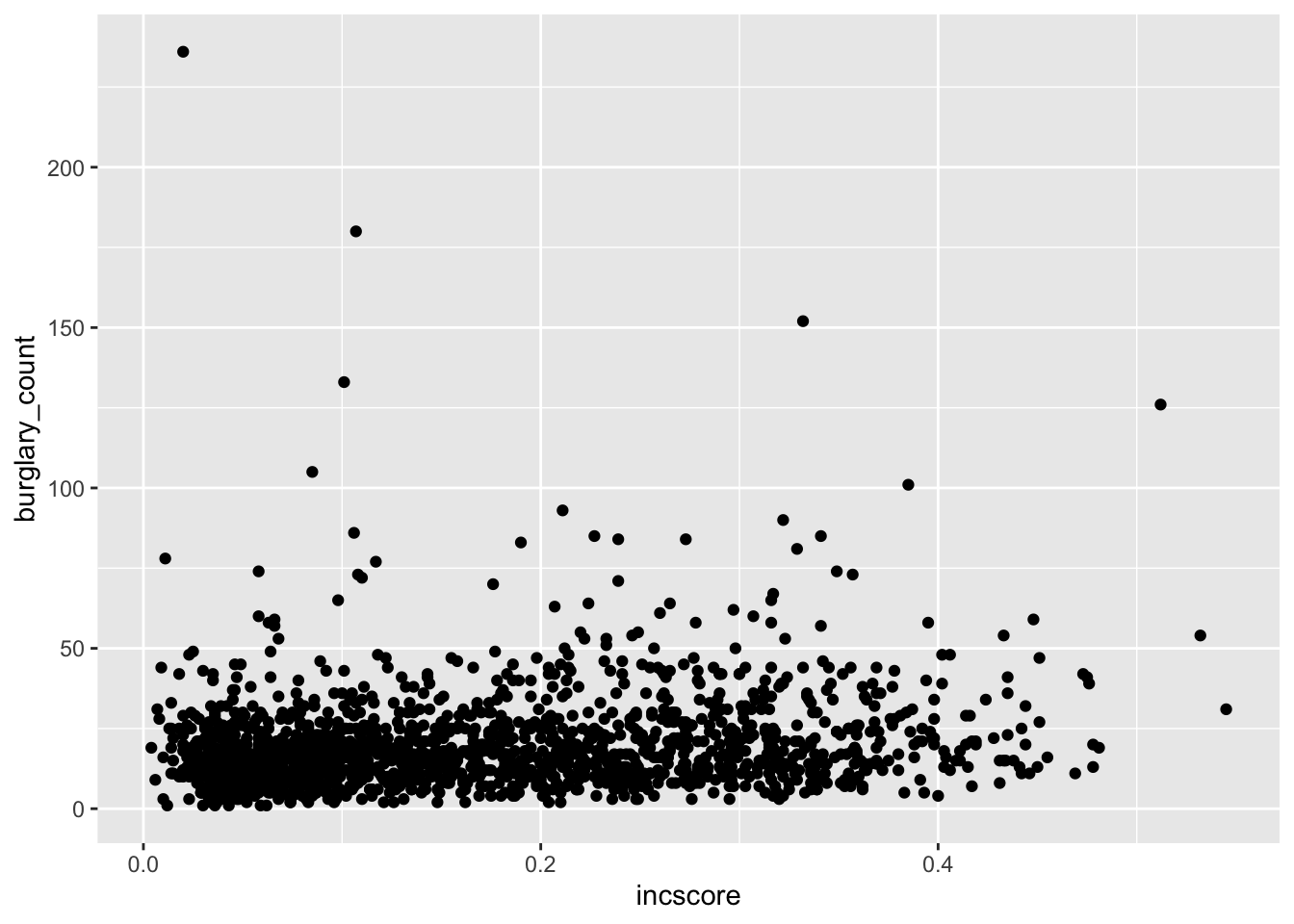
# We are saying, ‘Hey R, may you please make me a graphic using the data "burglary_df” and map the variables “incscore” to the x-axis and “burglary_count” to the y-axis, then pass this information through (using “ + ” ) to make a scatterplot?’Now the scatterplot in all its glory appears. What can you say about the relationship between deprivation and burglary victimisation? In your group google doc, type out what you think is the relationship between these two variables.
3.3.1.2 Activity 4: Adding a Third Variable to a Scatterplot
The real power in layered graphics comes from the ability to keep piling on the layers and tweaking components that make up the layers. For example, it would be helpful if we included other information like how local authorities may play a role in this relationship. Maybe income is positively associated with burglaries in one local authority, such as Bolton, but not in another, such as Bury. To explore this, we might want to colour each point by the variable LAname using the colour argument:
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, colour = LAname)) +
geom_point()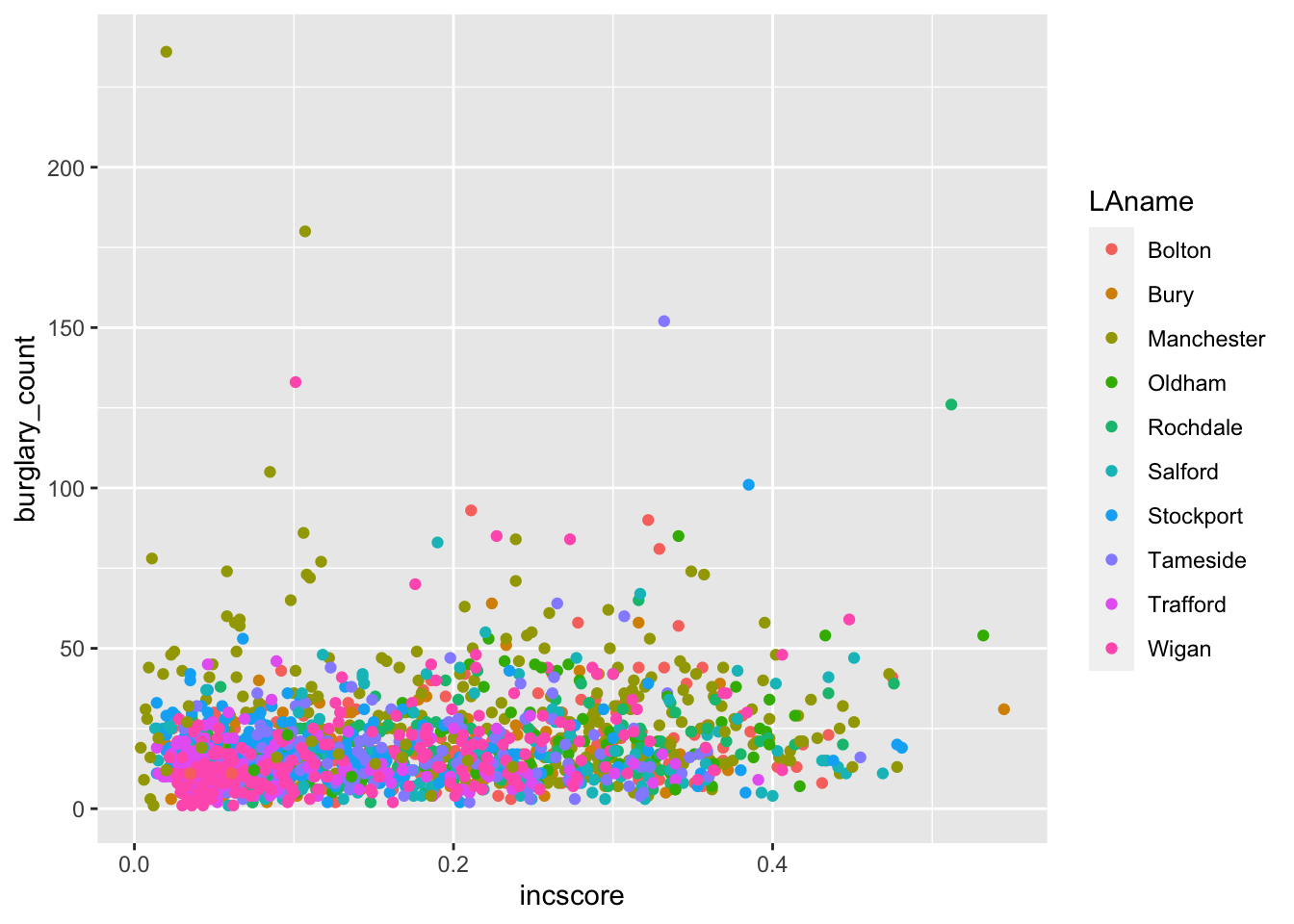
In your group google doc, state what you observe from this new visual. What sort of relationship does it seem to show between burglary counts and income? Do you think local authority plays a role? Do note the default colours, and think back to what we learned about accessibility last semester. In the next activity, we will address this!
As previously mentioned, a number of other functions are available for the geom_ function such as shape, linetype, size, fill, and alpha (transparency). But these depend on the geometry being used and the class of variable being mapped to the aesthetic. For example, try the shape aesthetic for LAname, which will vary the shape of each point according to local authority (hint: replace colour = with shape =). A warning message appears – what is it telling you? How can you see this reflected on the plot?
This relates to the grammar of graphics philosophy on how people understand information, and ggplot2 will warn you when it thinks the graphic is difficult to interpret or, worse, misleading.
3.3.1.3 Activity 5: Colours!
The colour palette that appeared for our previous scatterplot is a default one, and there are a number of default colour palettes available. We can specify a colour palette using an additional layer with the function scale_color_brewer(). For example:
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, color = LAname)) +
geom_point() +
scale_colour_brewer(palette = "Spectral")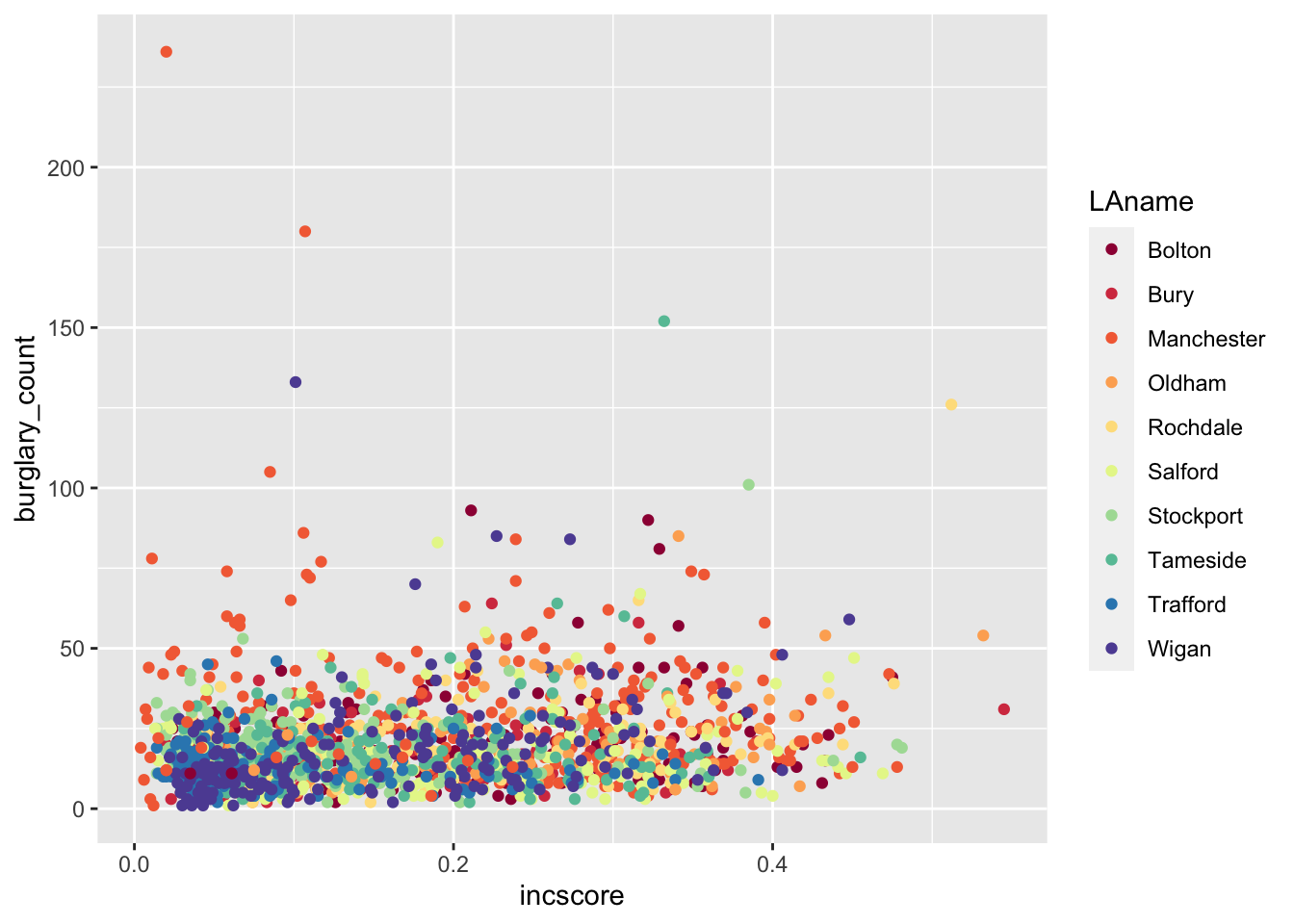
Does that look familiar? Last semester we used the website colorbrewer2.org/. The scale_colour_brewer() function takes palettes from this resource, and applies them to your charts.
In addition, the viridis package has a number of colour palettes that consider colour blindness where readers are unable to differentiate colours on the graphic. It is already integrated into ggplot2, so there is no need to install it separately. For example, we take the previous code and replace the last line with a viridis colour palette for categorical variables:
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, color = LAname)) +
geom_point() +
scale_color_viridis_d() # or scale_color_viridis_c() for a continuous variable 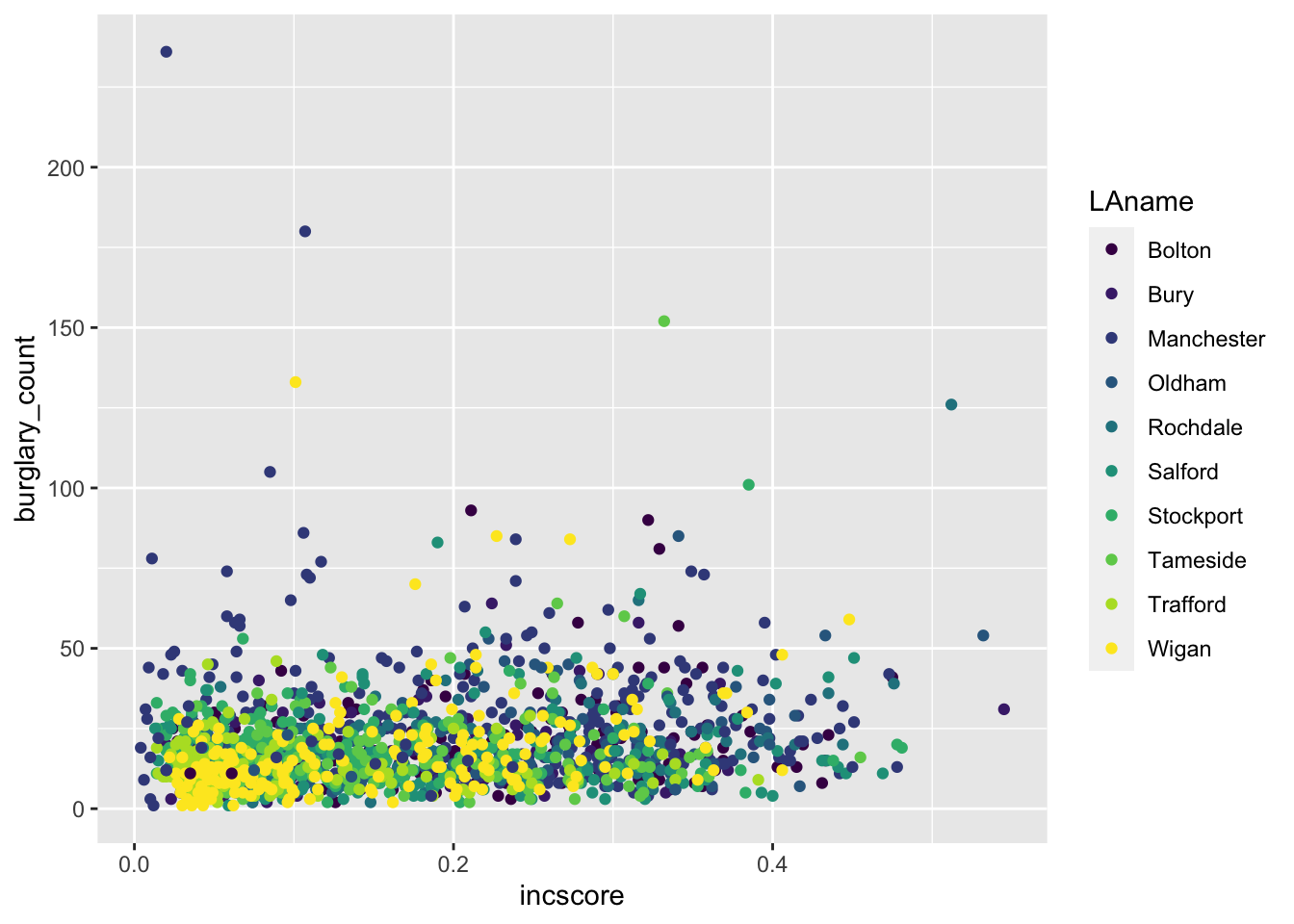
Now we have built up a graph to visualise the bivariate relationship between income deprivation score and burglary count per neighbourhood. Then, we introduced a third variable (i.e., multi-variable analysis) and brought in colour to add to the local authority. In the upcoming exercises, we will learn how to tweak the graphics so to make them even more our own!
3.3.1.4 Activity 6: Sizes & Transparency
Recall that the geometric object is about the data points themselves. You can change their appearance within the geom_point function. To increase the size of the points and make them transparent, we use the size and alpha arguments. The default for size is 1, so anything lower than 1 will make points smaller while anything larger than 1 will make the points bigger. The default for alpha is also 1, which means total opaqueness, so you can only go lower to make things more transparent. For example:
# Below, we want our data points to be a bit bigger ( 3 ) and more transparent ( 0.5 ) than the default
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, color = LAname)) +
geom_point(size = 3, alpha = 0.5) +
scale_color_brewer(palette = "Spectral")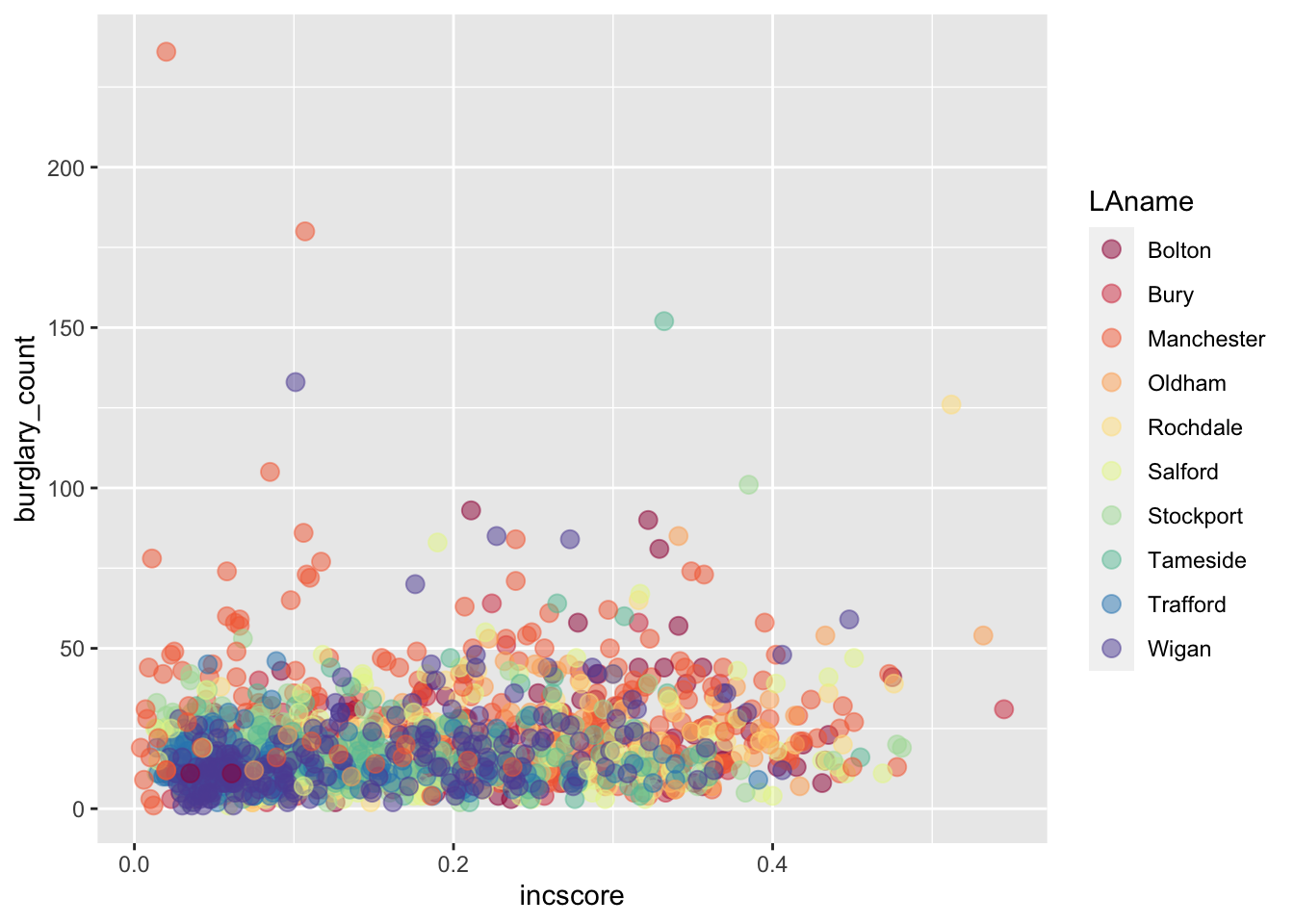
3.3.1.5 Activity 7: Labels
The graphic is looking good, but the labels will need tweaking if we do not like the default ones, which are our variable names. We use the labs() function to change the labels for the x and y axes as well as the graphic title:
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, color = LAname)) +
geom_point(size = 3, alpha = 0.5) +
scale_color_brewer(palette = "Spectral") +
labs(x = "Income score", y = "Burglary count", title = "Income and burglary and victimization", color = "Local Authority")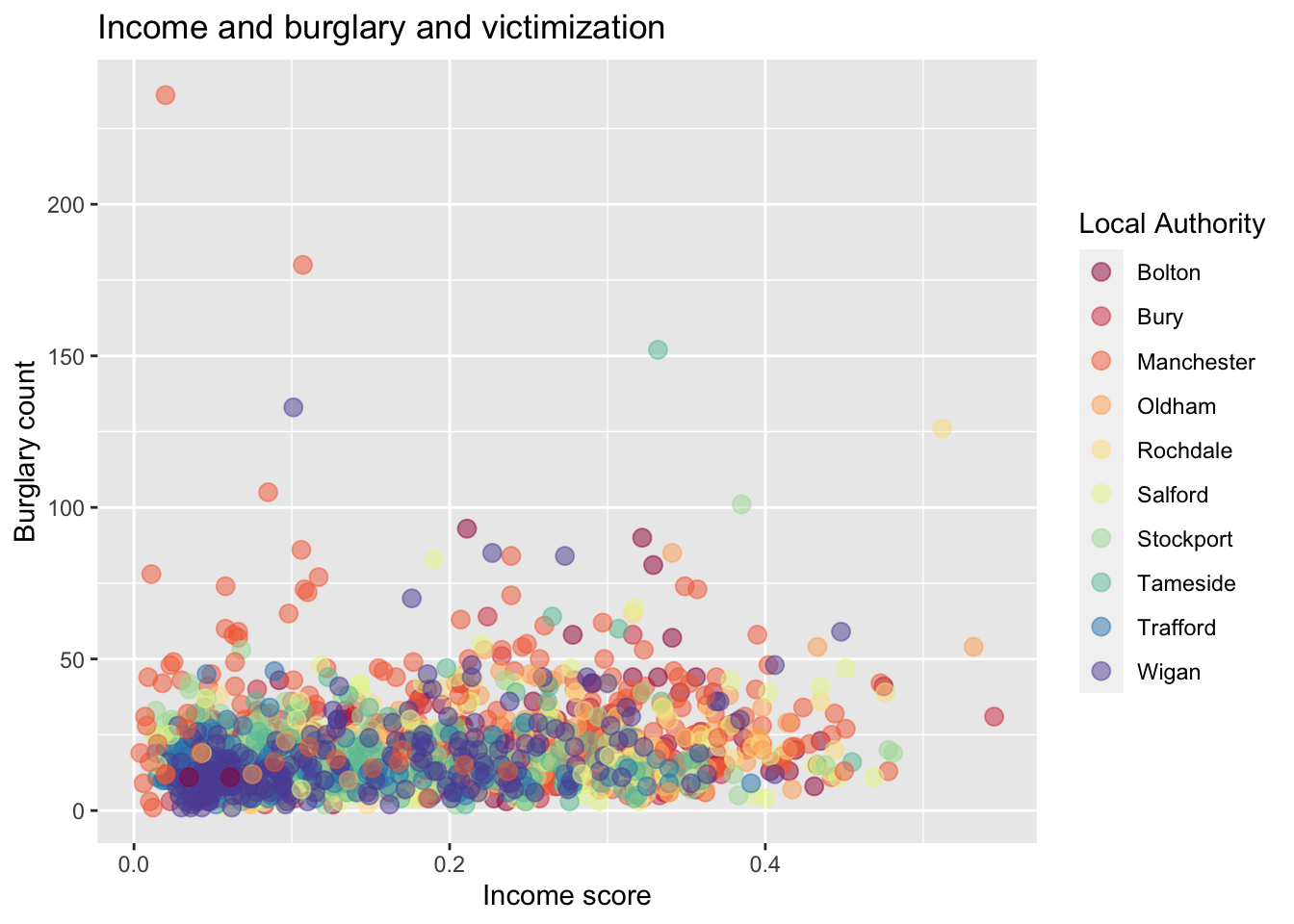
3.3.1.6 Activity 8: Built-in Themes
A final touch to your graphic can be the use of themes. These change the overall appearance of your graphic. The default theme we have for our graphic is theme_gray(), but we can go for a minimalist look by using theme_minimal (). There are a number of these customised themes like one that is inspired by The Economist ( theme_economist () ). To use special themes like The Economist, install the package ggthemes and load it.
# Changing graphic to the minimal theme with the last line of code
ggplot(data = burglary_df, mapping = aes(x = incscore, y = burglary_count, color = LAname)) +
geom_point(size = 3, alpha = 0.5) +
scale_color_brewer(palette = "Spectral") +
labs(x = "Income score", y = "Burglary count", title = "Income and burglary and victimization", caption = "Income score from 2019 IMD. Burglary counts from 2017." , color = "Local Authority") +
theme_minimal()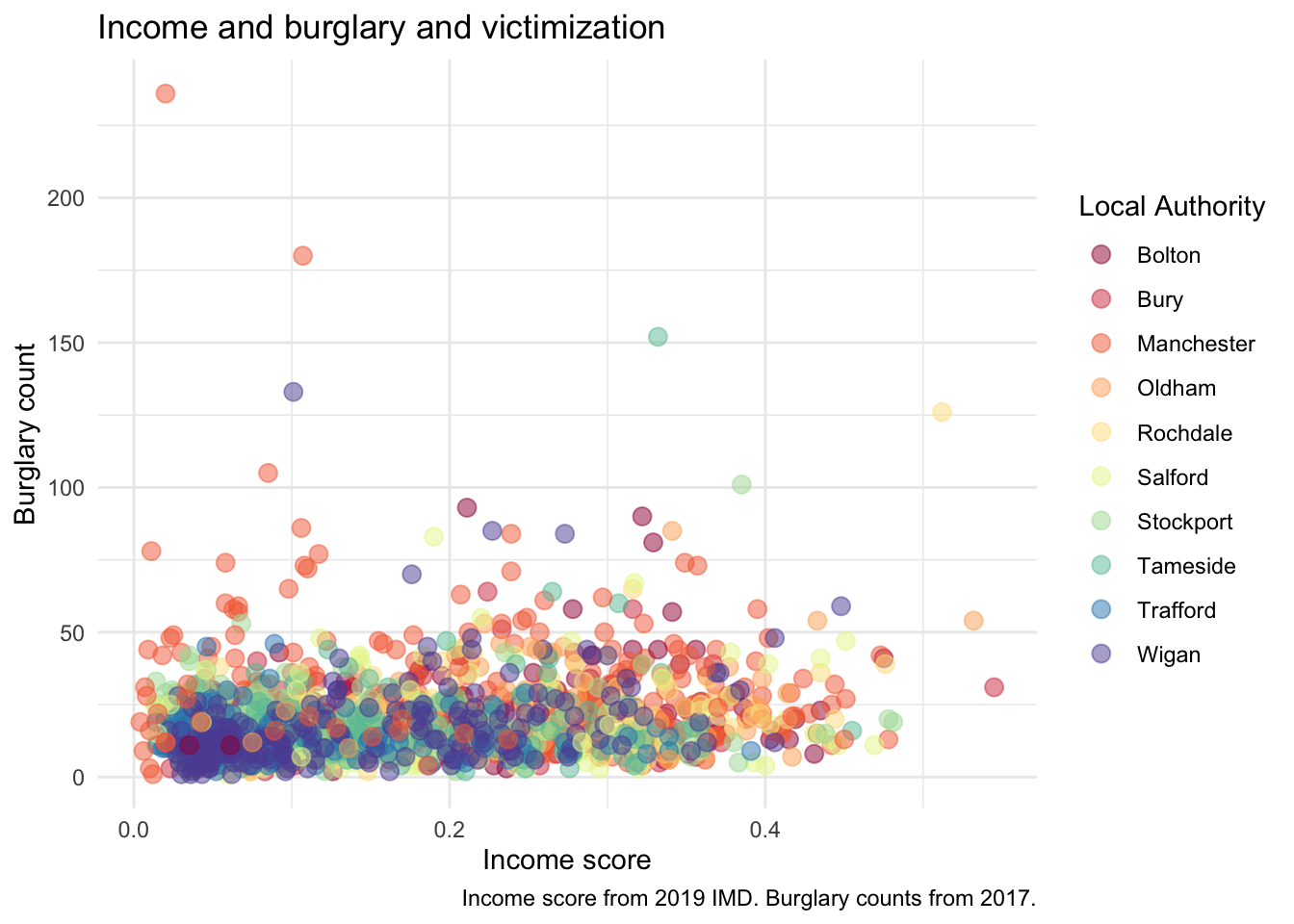
3.3.2 Graphs for Categorical Data
3.3.2.1 Activity 9: Bar graphs
To explore the count distribution of categorical variables, use the bar graph. We may be interested to know the number of neighbourhoods falling into each indice of the multiple deprivation (IMD) decile, a key indicator of criminality. Those in decile 1 are within the most deprived 10% of LSOAs nationally; those in decile 10 are considered within the least deprived 10% of LSOAs nationally.
The variable of interest, IMDdeci, is classed as numeric but we will need to treat it as a factor or else the default x-axis will include non-integer values like 7.5 .
Instead of making a new object, ggplot can calculate these frequencies by only specifying the x-axis and using the function as.factor():
ggplot(data = burglary_df) +
geom_bar(mapping = aes(x = as.factor(IMDdeci))) + # convert IMDdeci to a factor with as.factor
labs(x = "Deprivation Score", y = "Number of Lower Super Output Areas")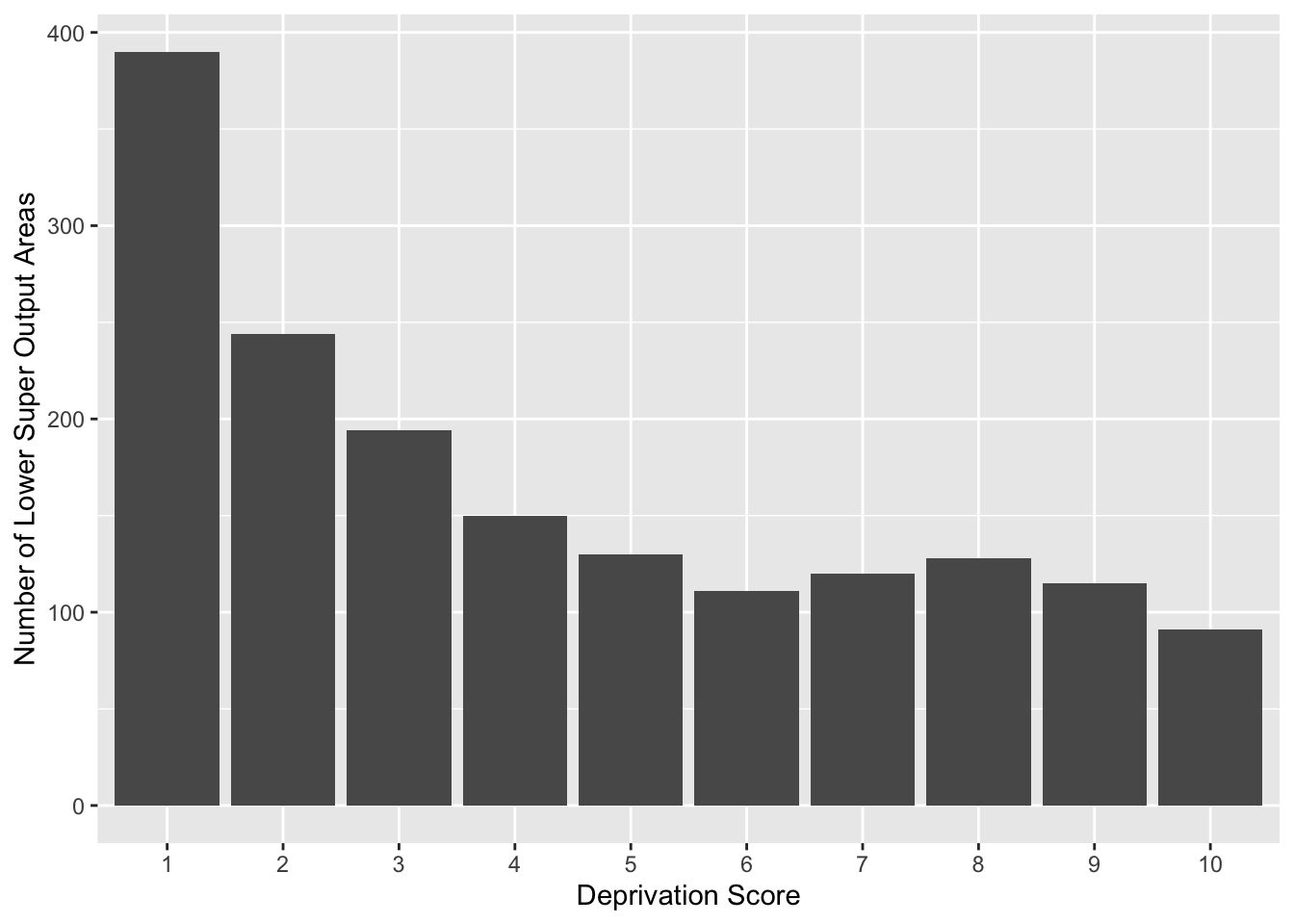
3.3.2.2 Grouped Bar Graphs
If we are interested in the distribution of deprivation like the previous bar graph but would like to see it by local authority, we can use the grouped bar graph, and specify the colour with the fill = parameter inside the aes() function.
Think back, however, to what we learned last semester, about row and column percentages, and how in bivariate analysis it is important to make decisions that will affect how our readers interpret our data. For example, if we fill the colour of each bar by local authority, we get a chart like this:
# The ‘dodge’ position means that the bars avoid or ‘dodge’ each other
ggplot(data = burglary_df) +
geom_bar(mapping = aes(x = as.factor(IMDdeci), fill = LAname), position = "stack") +
scale_fill_viridis_d() +
labs(x = "Deprivation Score", y = "Number of Lower Super Output Areas", fill = "Local Authority")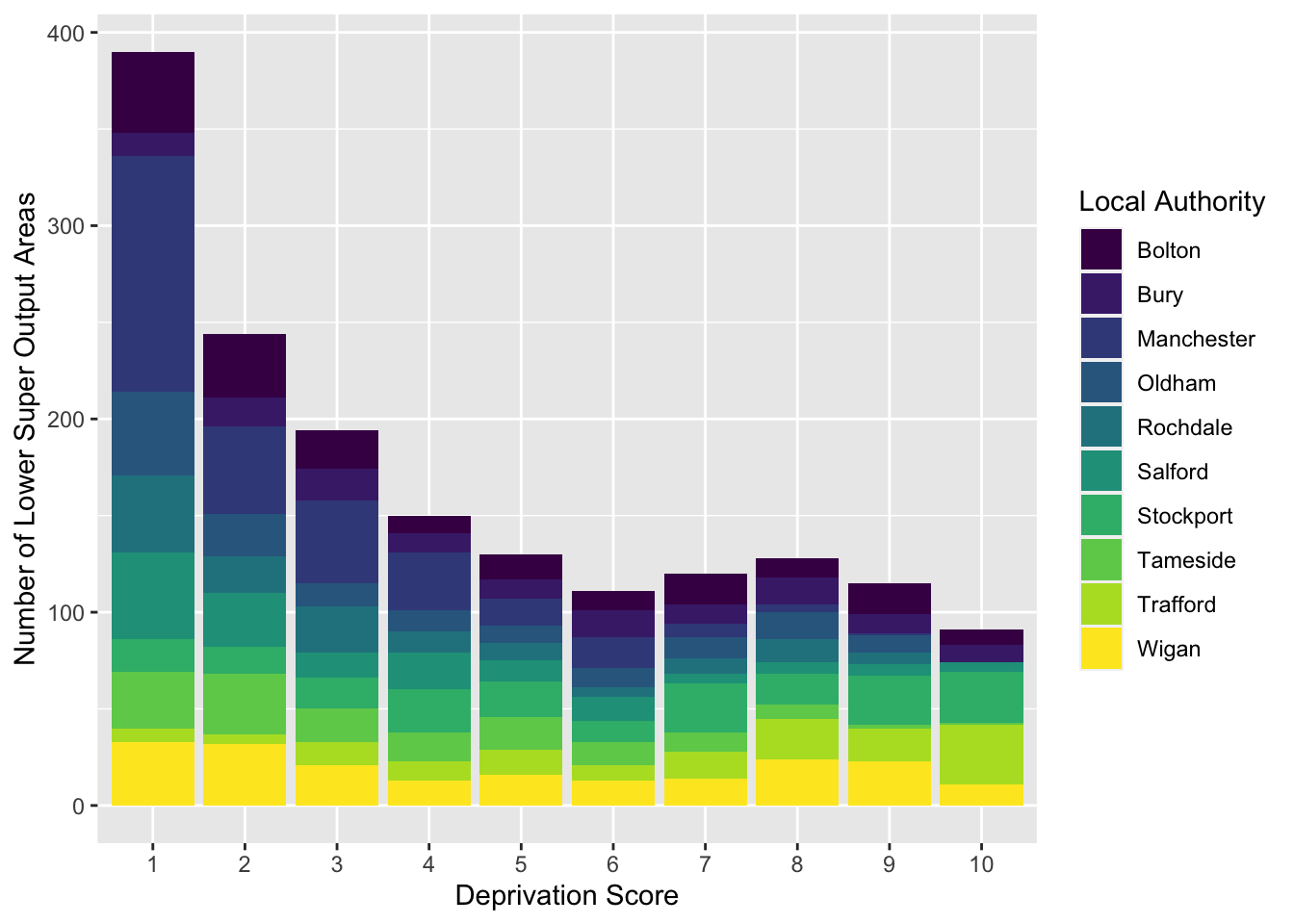
How do the different local authorities compare in terms of the distribution of deprived neighbourhoods? It can be a bit tough to say. But what about if we flip these:
# We switch the positions of LAname and IMDdeci in the second line of code in this example
ggplot(data = burglary_df) +
geom_bar(mapping = aes(x = LAname, fill = as.factor(IMDdeci)), position = "stack") +
scale_fill_viridis_d() +
labs(x = "Local Authority", y = "Number of Lower Super Output Areas", fill = "Deprivation Score")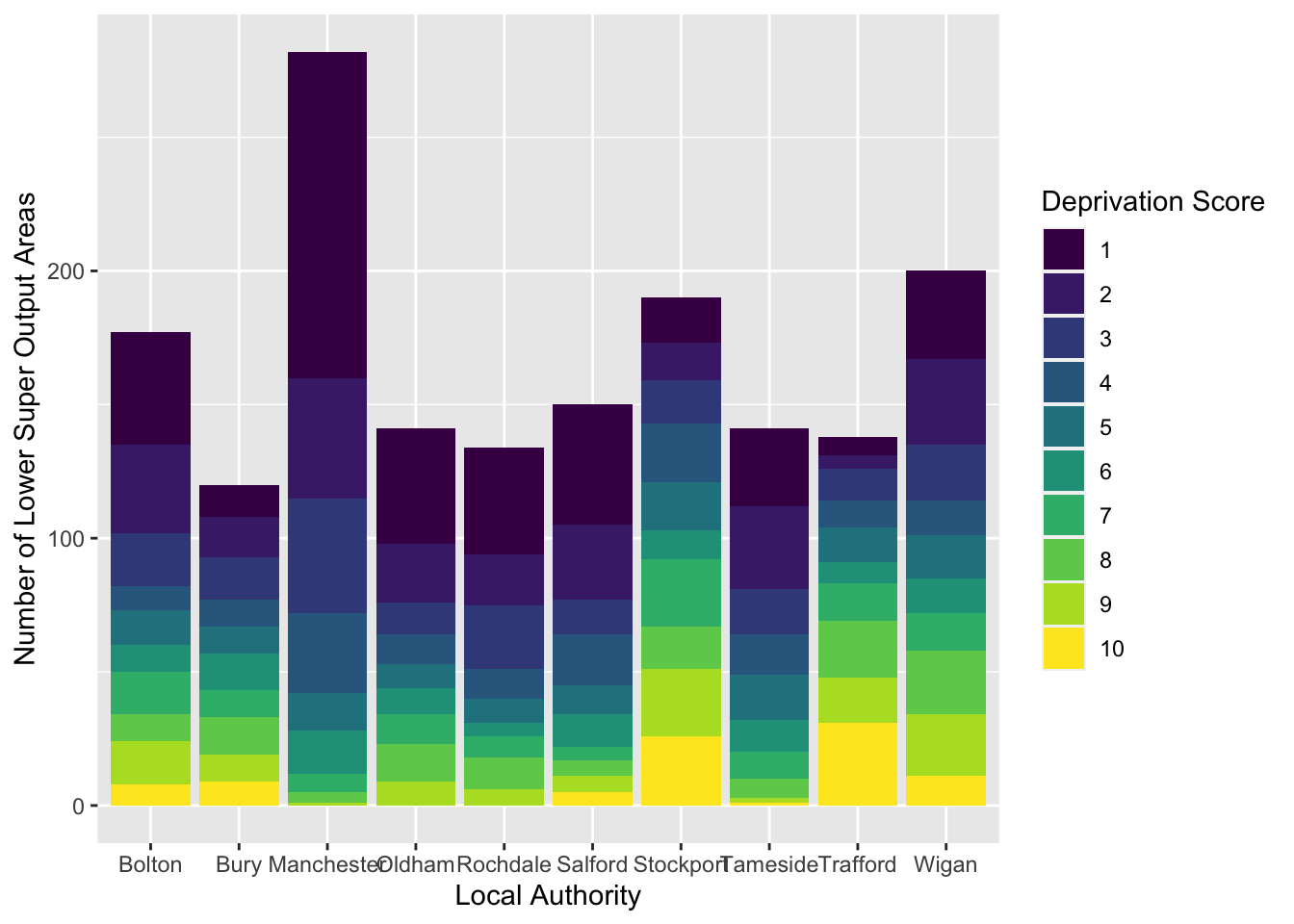
This seems clearer.
In your google doc, state what you observe from the bar graph and grouped bar graph depicting the relationship between deprivation and LSOAs.
Note: in the previous example, you might have noticed – inside the geom_bar() function, after the closing bracket of the aes() function – the parameter , position = "stack". This means that we get a stacked bar chart. You could change this to , position = "dodge", which would give you a clustered bar chart. Like so:
# Instead of stack, the ‘dodge’ position means that the bars avoid or ‘dodge’ each other
ggplot(data = burglary_df) +
geom_bar(mapping = aes(x = LAname, fill = as.factor(IMDdeci)), position = "dodge") +
scale_fill_viridis_d() +
labs(x = "Local Authority", y = "Number of Lower Super Output Areas", fill = "Deprivation Score")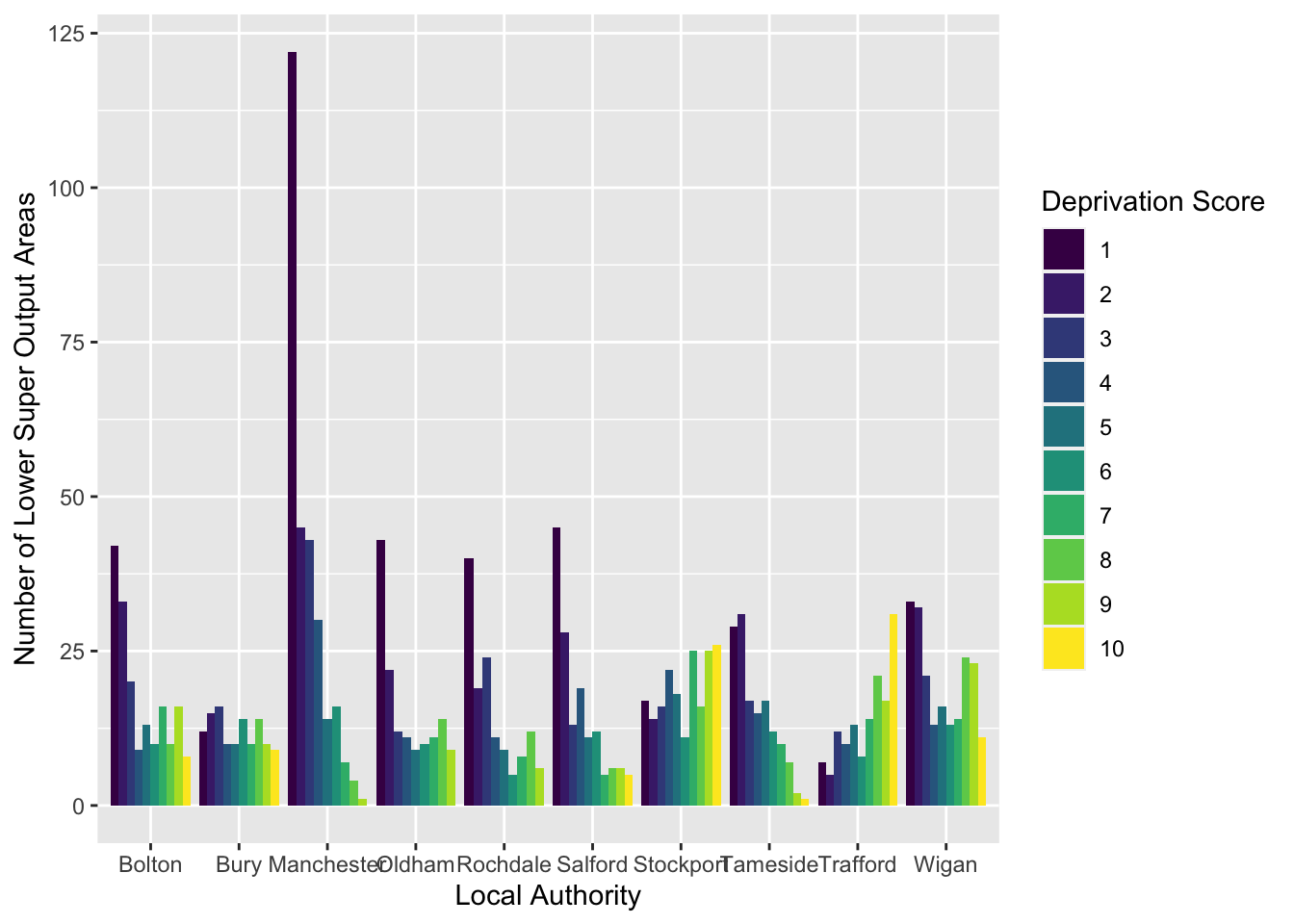
This might also be another way to display your data. There are advantages and disadvantages to both the stacked and clustered bar charts, and it has to do with what they hide and show!
3.3.2.3 Multiple Bar Graphs
Another useful visual is multiple bar graphs. This creates different plots for each level of a factor instead of putting lots of information into one graphic. Using the function facet_wrap (), we make the information obtained from the previous scatterplot, where we coloured in each point by local authority, clearer.
Although the scatterplot uses numeric variables, we use this information by local authority, and LAname is classed as factor:
# To facet the scatterplot by local authority, ‘ ~ ‘ is used next to ‘LAname’
ggplot(data = burglary_df) +
geom_point(mapping = aes(x = incscore, y = burglary_count)) +
facet_wrap(~LAname)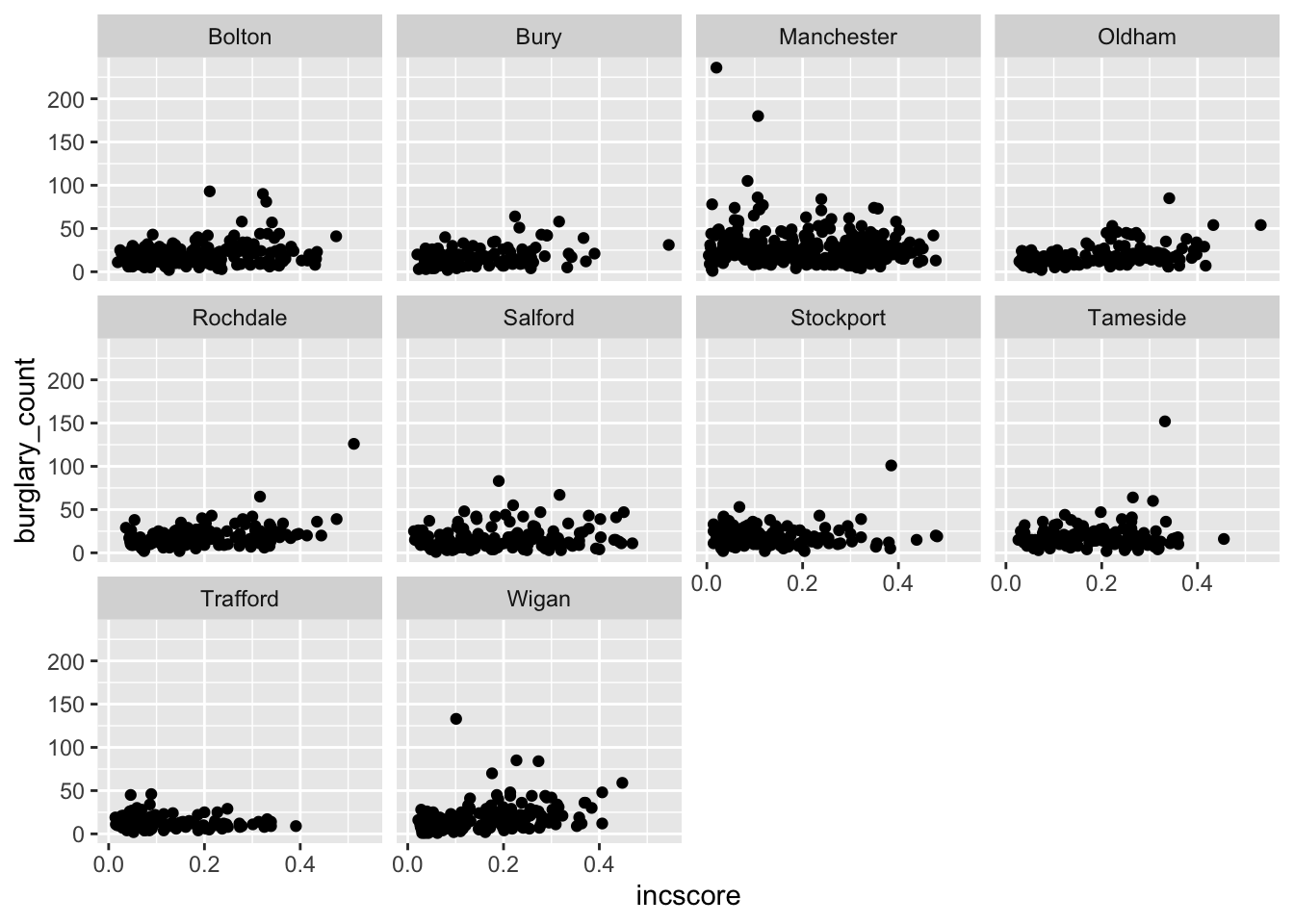
# By default, facet_wrap fixes the y-axis of each graph to make comparisons easierIt is important to choose an appropriate graph, so thought is required. May the following graphic be fair warning:
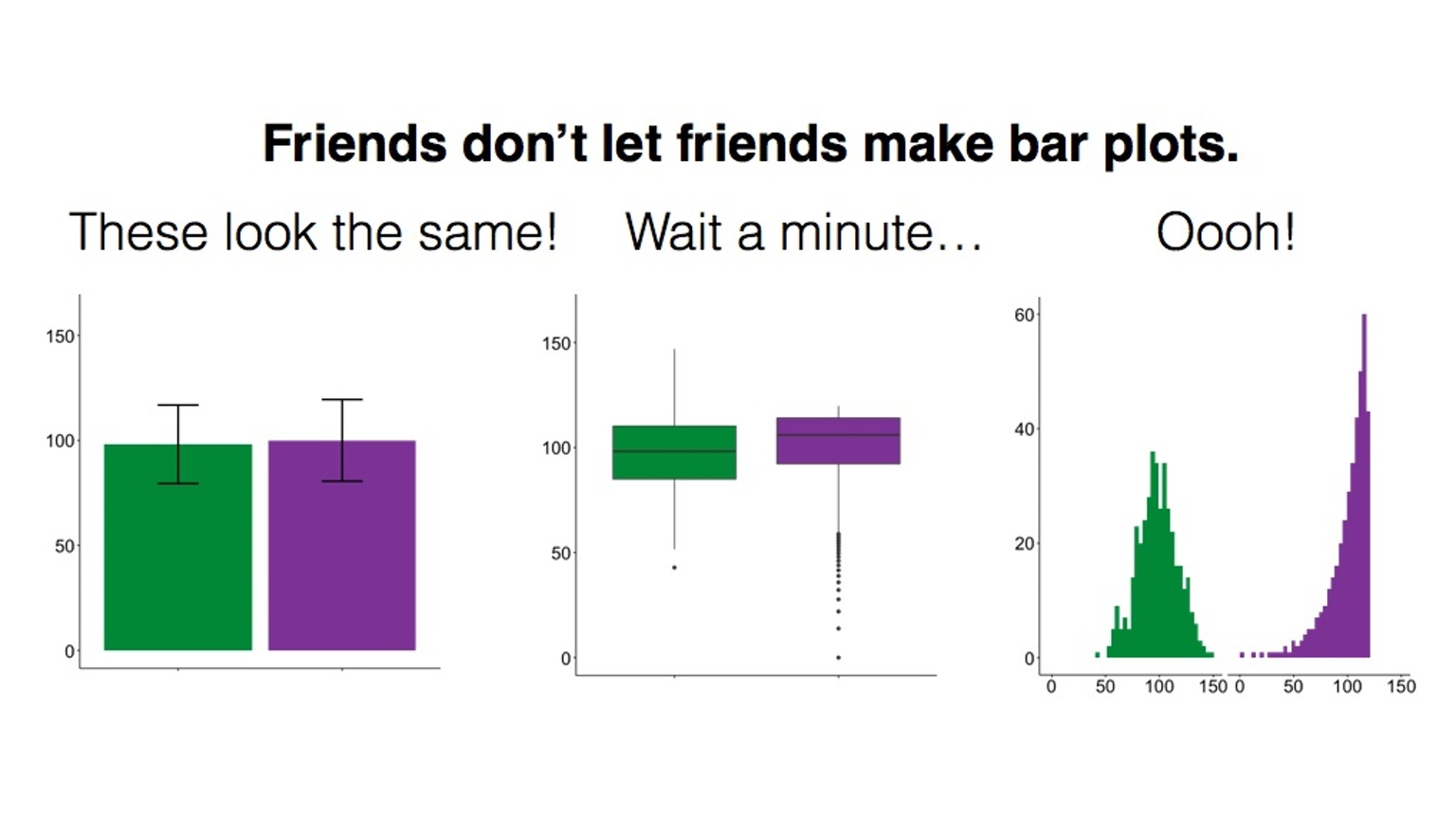
Figure 3.8 Friends don’t let friends do this
3.3.3 Graphs for Numeric Data
3.3.3.1 Activity 10: Histograms
Histograms differ from scatterplots because they require only one numeric variable and they create bins, visualized as bars, to count the frequency of each bar. We create a histogram of the variable IMDscore, the overall score of deprivation in each neighbourhood:
ggplot(data = burglary_df, mapping = aes(x = IMDscore)) +
geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.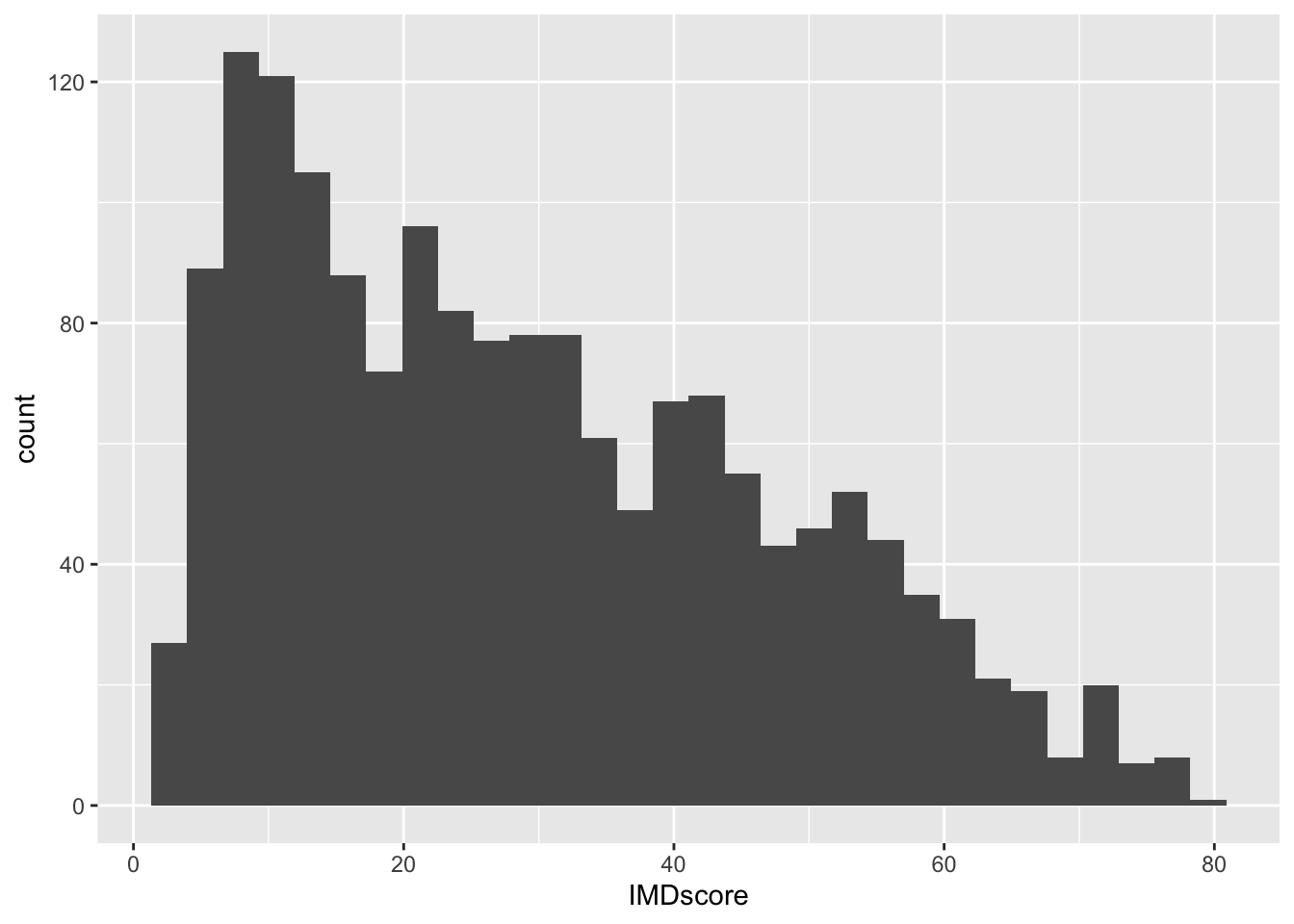
How the histogram looks, and therefore, the conclusions drawn from the visual, are sensitive to the number of bins. You should try different specifications of the bin-width until you find one that tells the complete and concise story of the data. Specifying the size of bins is done using the argument bin_width =; the default size is 30 and you can change this to get a rougher or a more granular idea:
# Using bin-width of 1 we are essentially creating a bar for every increase in level of deprivation
ggplot(data = burglary_df, mapping = aes(x = IMDscore)) +
geom_histogram(binwidth = 1)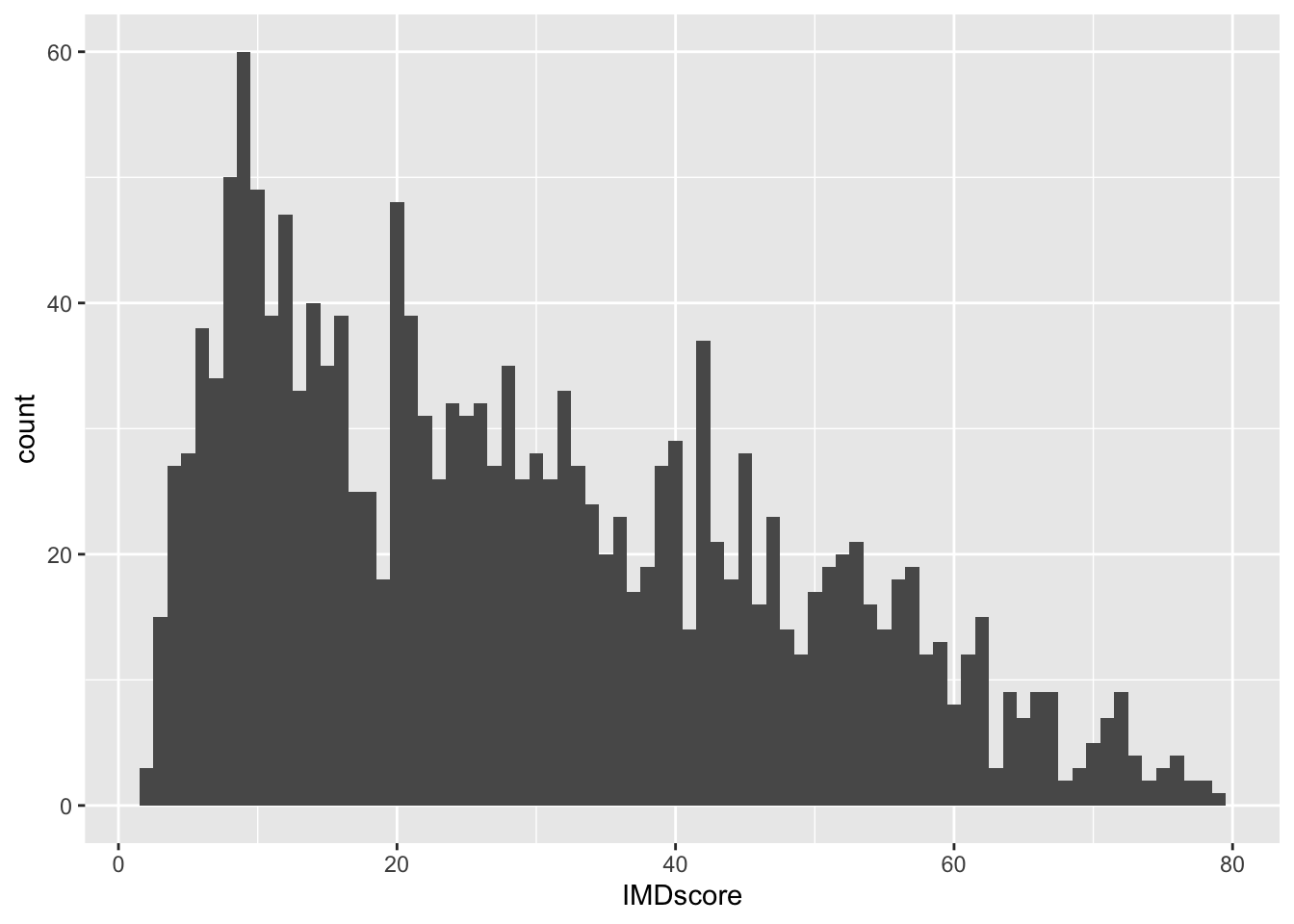
Play around with the bin widths to find which one looks the most visually comprehensible. In your google doc, state what bin width you think does the job, and why.
3.3.3.2 Activity 11: Line Graphs
A very good way of visualizing trends over time are line graphs. For this, let us use the monthly_df data frame. Ensure it is loaded into your environment. Have a look at the structure of these data to get to know them.
The data is in long format: we have a single month variable for 12 months’ worth of data (rather than one variable or column for each month). Setting longitudinal data up in long format allows us to specify the aesthetics (e.g., x- and y-axes) easily.
For a line graph, we use the function geom_line(). We plan to plot the counts to show the trends of different crimes over the course of the year. Our time variable, month, should run along the x-axis, and the count variable, n, should run on the y-axis.
To show each crime type separately, we use the group aesthetic and a new aesthetic, linetype, which uses different patterns for each group. To show our time measurement points, we also add geom_point ():
ggplot(data = monthly_df, aes(x = as.factor(Month), y = n, group = crime_type, linetype = crime_type)) +
geom_line() +
geom_point()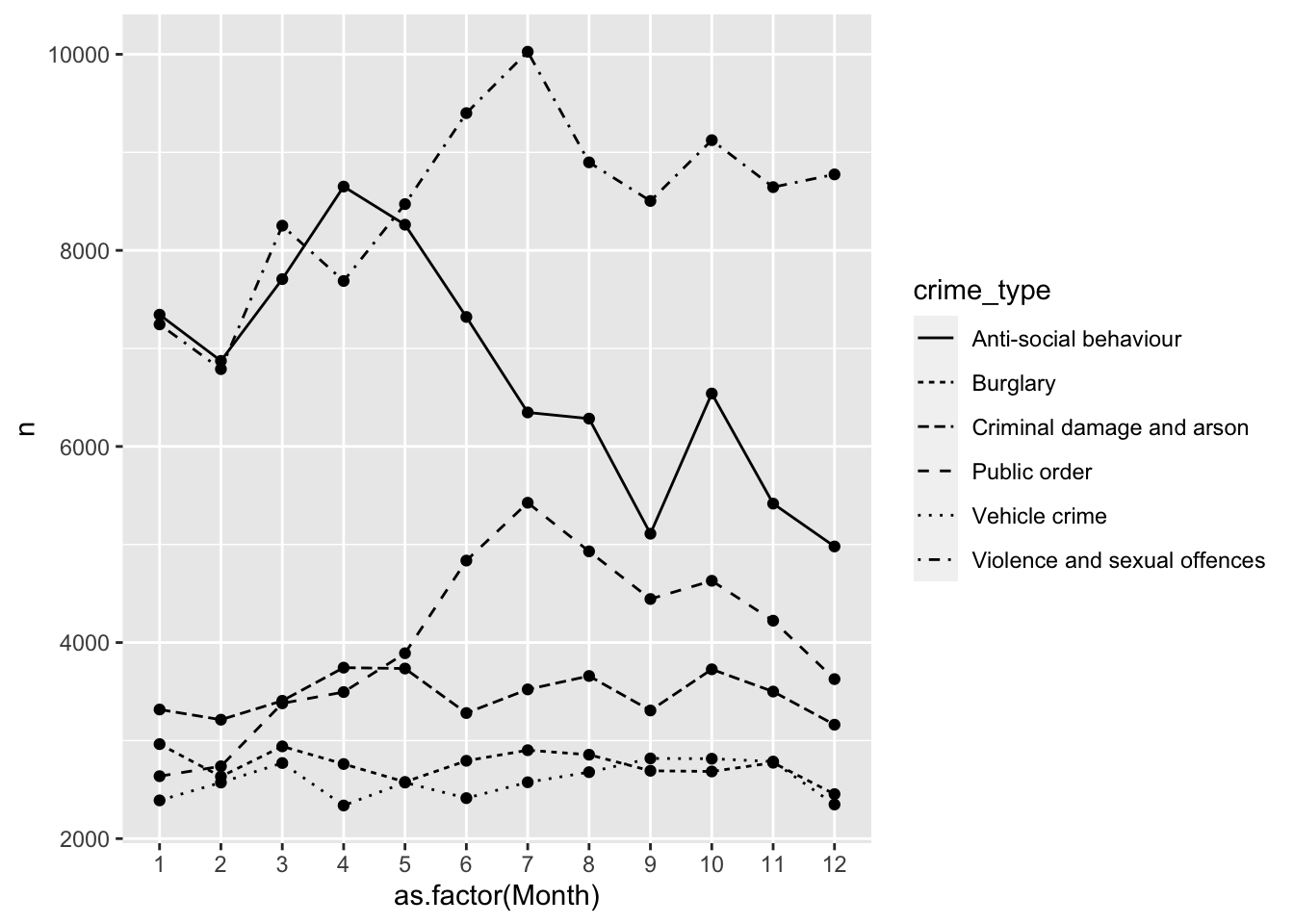
# We are saying, ‘Hey R, may you please make a graphic using the data frame “monthly_df”, and map the variable “month” (turning it into a factor) to the x-axis and “n” to the y-axis, and group this information by “crime_type”, showing different patterns for each crime type, then pass this information through (“ +”) to make a line graph, and pass this information through (“ +”) to make a scatterplot of the time points too?’Now, in your google doc, state what you observe from this line graph on different crimes throughout the months.
3.3.3.3 Activity 12: Boxplots
If you want more information about your data than a histogram can give, a box (and whisker) plot may be what you are looking for. A boxplot visualizes the minimum, maximum, interquartile range, the median, and any unusual observations - your five-number summary!
For this example, we return to the burglary_df data, and focus on the distribution of burglary counts. In addition, we make a boxplot for each deprivation decile to show how LSOAs in the most deprived deciles often have higher median burglary counts.
We send all of this information, the boxplots, into one object called my_whisker_plot, to which we can return in case:
my_whisker_plot <- ggplot(data = burglary_df) +
geom_boxplot(mapping = aes(x = as.factor(IMDdeci), y = burglary_count, group = as.factor(IMDdeci), fill = as.factor(IMDdeci)))
my_whisker_plot +
labs(x = "Deprivation Scale", y = "Number of Burglaries")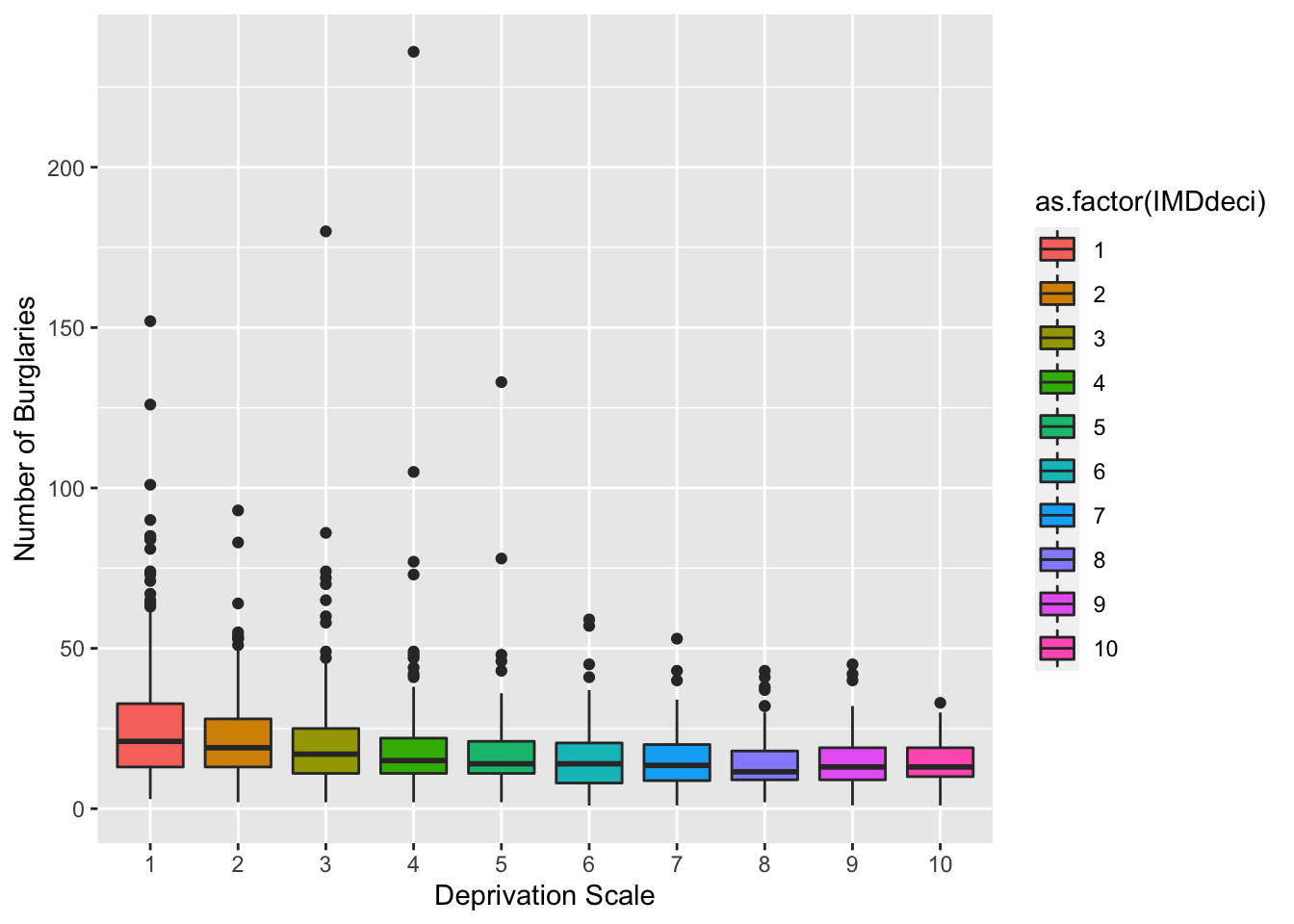
In your group google doc, state what you observe from your newly created boxplot.
3.4 SUMMARY
Today was about using a popular package called ggplot2 for effectively visualizing data. We learn this because it is important to understand our data before embarking on more complex analyses. If we do not understand our data beforehand, we risk misinterpreting what the data are trying to tell us. The package is based on this approach called Grammar of Graphics, which proposes a ‘grammar’ to describe and construct statistical graphics. The package, however, sees the creation of data visuals accomplished through layers.
Our first topic we learned was about these layers, comprising data, aesthetics, and geometric objects. As a final touch, themes changed the overall appearance of your graphic. Our second and third topics introduced us to graphs that we can use for all types of variables, and how to create them in ggplot2. One example was the histogram, whereby adjusting the width of the bins helped for better interpretation of the data.
Hurrah: homework time!
3.4.1 ANSWERS TO ACTIVITIES:
- burglary_df: 1,673 observations, 9 variables ; monthly_df: 73 observations, 3 variables
- burglary_df: n= 1,673 LSOAs; (2) monthly_df: n= 72 months
- Hard to say…
- Roughly: most areas have burglary counts below 50
- N/A
- N/A
- N/A
- N/A
- Roughly: The most number of LSOAs are in decile 1, meaning they are within the 10% of the most deprived LSOAS, and in the final and stacked grouped bar graph, LSOAs from Manchester have a large number in decile 1.
- N/A
- Roughly: Violence and sexual offences are the highest compared to other crimes and reaches its peak in the summer months. Antisocial behaviour rises from February to April, then declines, hitting a low point in September before rising again.
- Roughly: Decile 1 has highest median (about 25) compared to other deciles but with many outliers. Decile 4 has the most extreme outlier of about 250 burglaries.