Chapter 9 Regression
OLS & Logistic Regressions
Learning Outcomes:
- Learn how and when to use ordinary least squares and logistic regressions
- Understand and interpret the outputs generated from running regression
- Test for model fit and whether assumptions are met
Today’s Learning Tools:
Total number of activities: 12
Data:
- Crime Survey for England and Wales (CSEW) from 2013 to 2014 sweep teaching dataset
Arrestsfrom theeffectspackage
Packages:
armcareffectsggplot2herelessRsjPlottidyverse
Functions introduced (and packages to which they belong)
complete.cases(): Returns only complete cases that do not have NAs (base R)display(): Gives a clean printout of lm, glm, and other such objects (arm)lm(): Fit linear models (base R)Logit(): Fit logistic regression models with less typing (lessR)plot_model(): Plots odds ratios and their confidence intervals (sjPlot)relevel(): Reorders the levels of a factor (base R)tab_model(): Creates HTML tables summarising regression models (sjPlot)vif(): Calculate the variance inflation for OLS or other linear models (car)
9.1 Multiple and Simultaneous Relationships
Our learning on inferential statistics, so far, has been on single relationships between two variables. One of the major drawbacks of previous analyses of single relationships is that, even though you are able to test for statistical significance, you cannot ascertain prediction very well. In other words, you were unable to say for certain that one variable predicted another variable; we merely could say ‘there was a relationship’ or ‘there was no relationship’.
Although we got into the habit of arranging our variables as independent and dependent variables, these terms are more relevant to regression. The reason is, not only can we establish whether relationships are statistically significant, we also can say with relatively more clarity, how that relationship looks like – how change in one variable may be impacting change in the other variable.
Another major drawback of previous analyses of bivariate relationships is that you are less certain about whether the relationship and its effect size would still hold in the face of other variables. For example, would a significant relationship between peer group and violence still exist when the relationship between unemployment and violence is considered? How about the relationship between previous criminal justice contacts and violence? This last lesson is on analyses that establish predictive relationships and test multiple relationships between two variables at the same time.
9.2 Today’s 3
Our main topic of the day is regression and we learn two forms: ordinary least squares (OLS) and logistic. The former is applied to dependent variables that are measured at interval or ratio level, while the latter is applied to dependent variables that are binary and measured at the nominal level. The three topics are: motivating regression; interpreting OLS regression; and logistic regression.
9.2.1 Motivating Regression
In science, one of our main concerns is to develop models of the world – models that help us to better understand the world or to predict how things will develop. You can read more about modelling in scientific research here. Statistics provides a set of tools that help researchers build and test scientific models.
Our models can be simple. We may think that unemployment is a variable that can help us to understand why cities differ in their level of violent crime. We could express such a model like Figure 9.1:
Figure 9.1 Simple Model
But we know the world is complex, and that likely, there are other things that may help us to understand why some cities have more violent crime than others. So, we want to have tools that allow us to examine such models that include other variables. For example, the one below, Figure 9.2:
Figure 9.2 A relatively complex model
In this lesson, we are going to cover regression analysis or, rather, we are will begin to talk about it.
Specifically, we start with a popular technique called ordinary least squares (OLS) regression. It is used to explore whether one or multiple independent variables (IV or \(X\)) can predict or explain the variation in the dependent variable (DV or \(Y\)).
When multiple IVs are included simultaneously, they are called covariates; when only one IV is used, the OLS regression is called bivariate regression or simple regression. OLS regression has been the mainstay analysis in the social sciences.
9.2.1.1 Activity 1: Setting up! The R prep routine
To begin, we do the following:
Open up your existing
RprojectInstall and load the required packages shown above
Load the dataset ‘csew1314_teaching.csv’, using the
read_csv()functionName the data frame
df
9.2.1.2 Activity 2: Getting to know your data
The first step in any analysis is to get to know your data. We have been here before: read the codebook/ data dictionary; run summary statistics for your numeric variables, frequency distributions for your categorical variables (see Lesson 4); and visualise your variables (see Lesson 3). This will help you detect any anomalies and give you a sense for what you have.
Some variables of interest that we could explore are perception of antisocial behaviour (antisocx) and whether it is associated with other variables such as age (age), gender (gender), victimisation experience (bcsvictim), and confidence in the criminal justice system (confx).
For example, if we start with perception of antisocial behaviour (antisocx) and age (age), we would visualise our variable distributions:
# Histogram for age
ggplot(data = df, mapping = aes(x = age)) +
geom_histogram(binwidth = .5)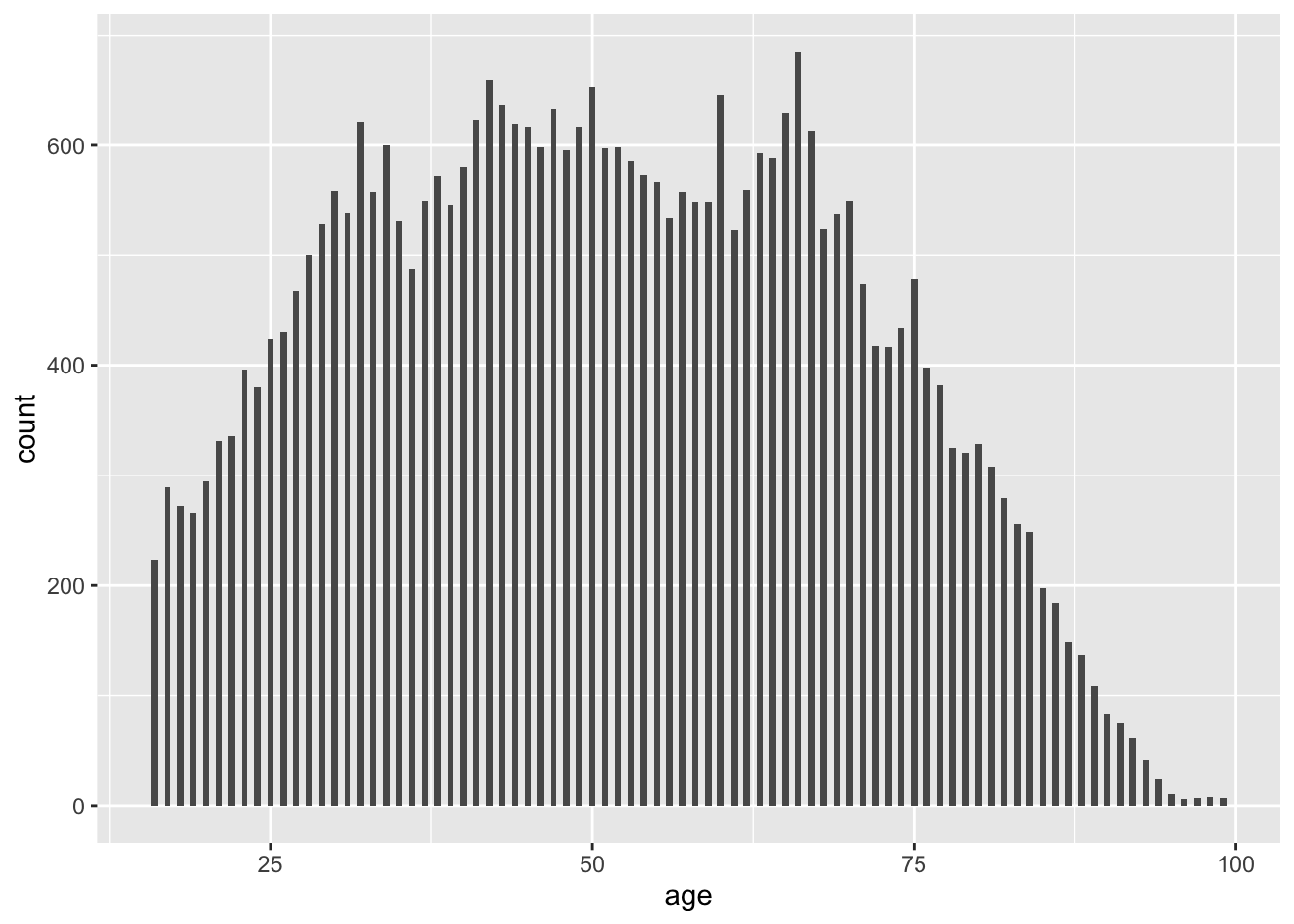
# Histogram for 'antisocx'
ggplot(data = df, mapping = aes(x = antisocx)) +
geom_histogram(binwidth = .2) # antisocx is negatively skewed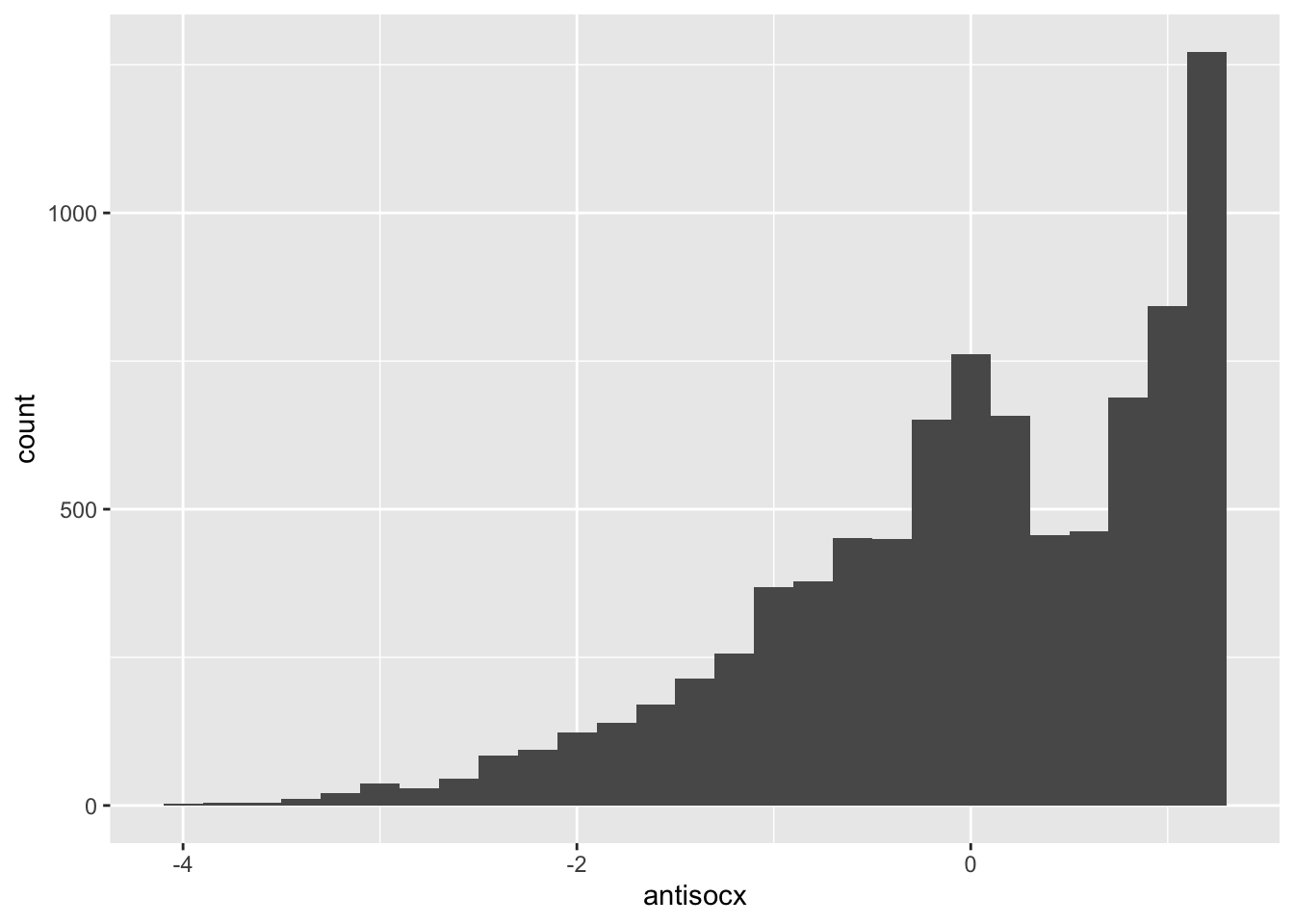
9.2.1.3 Activity 3: Exploring your data further: deleting missing data
We need to look for any missing data as it may affect getting to know our data:
# Age variable
summary(df$age) # NA = 188## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 16.00 36.00 51.00 51.19 66.00 99.00 118# Antisocial variable
summary(df$antisocx) # NA = 26695## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## -4.015 -0.559 0.177 0.000 0.788 1.215 26695Both variables have missing data. You could ignore the ‘NAs’, as when we run regression, it will conduct a listwise deletion, where observations are dropped from your analysis if they have missing data on either the IV (\(X\)) or the DV (\(Y\)). But as we want descriptive statistics of only observations we will be using, we will delete those that will be dropped anyway.
We use the complete.cases() function to keep cases that have valid responses in both the IV and DV:
# Start with 35,371 cases
nrow(df) ## [1] 35371# Retain only complete cases
df <- df %>% filter(complete.cases(df$age) & complete.cases(df$antisocx))
# Left with 8,650 cases after dropping NAs
nrow(df) ## [1] 8650Now we can get to know the data!
# Summaries of just the 8,650 cases
summary(df$age)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 16.00 36.00 50.00 50.82 66.00 98.00summary(df$antisocx)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -4.014557 -0.552077 0.178767 0.001823 0.788219 1.215267
9.2.1.4 Activity 4: What questions can regression answer?
For this example, we are interested in the bivariate relationship between age (\(X\)) and perception of antisocial behaviour (\(Y\)).
Our research question is: ‘Does age predict perceived level of antisocial behaviour in one’s neighbourhood?’ Our null and alternative hypotheses are as follows:
\(H_0\): Age does not predict perceived level of antisocial behaviour in one’s neighbourhood.
\(H_A\): Age does predict perceived level of antisocial behaviour in one’s neighbourhood.
Returning to the concept of models as to answer ‘what questions can regression answer?’, a model can be anything that allows for inferences about a population (from a sample) to be drawn. For example, earlier in the semester, we used the mean, which could be used to draw inferences. Here, we are interested developing a model to predict perception of antisocial behaviour (antisocx).
If Reka picked a person at random from the sample, what would be your best guess on that random person’s perceived level of neighbourhood antisocial behaviour? Likely, you would say a value near the mean (M = 0.001823) of the sample. This is a good guess, but we do not know how accurate this is.
A model helps our guesses become more accurate. Once we model the relationship between antisocx, this dependent variable, and an independent variable, we can use the model to help improve our guesses. Let us start by looking at a scatterplot:
# Checking out how the variables covary together
# (See Lesson 8, section 8.2.1.1 on covariation)
ggplot(df, aes(x = age, y = antisocx)) +
geom_point(alpha=.2, position="jitter")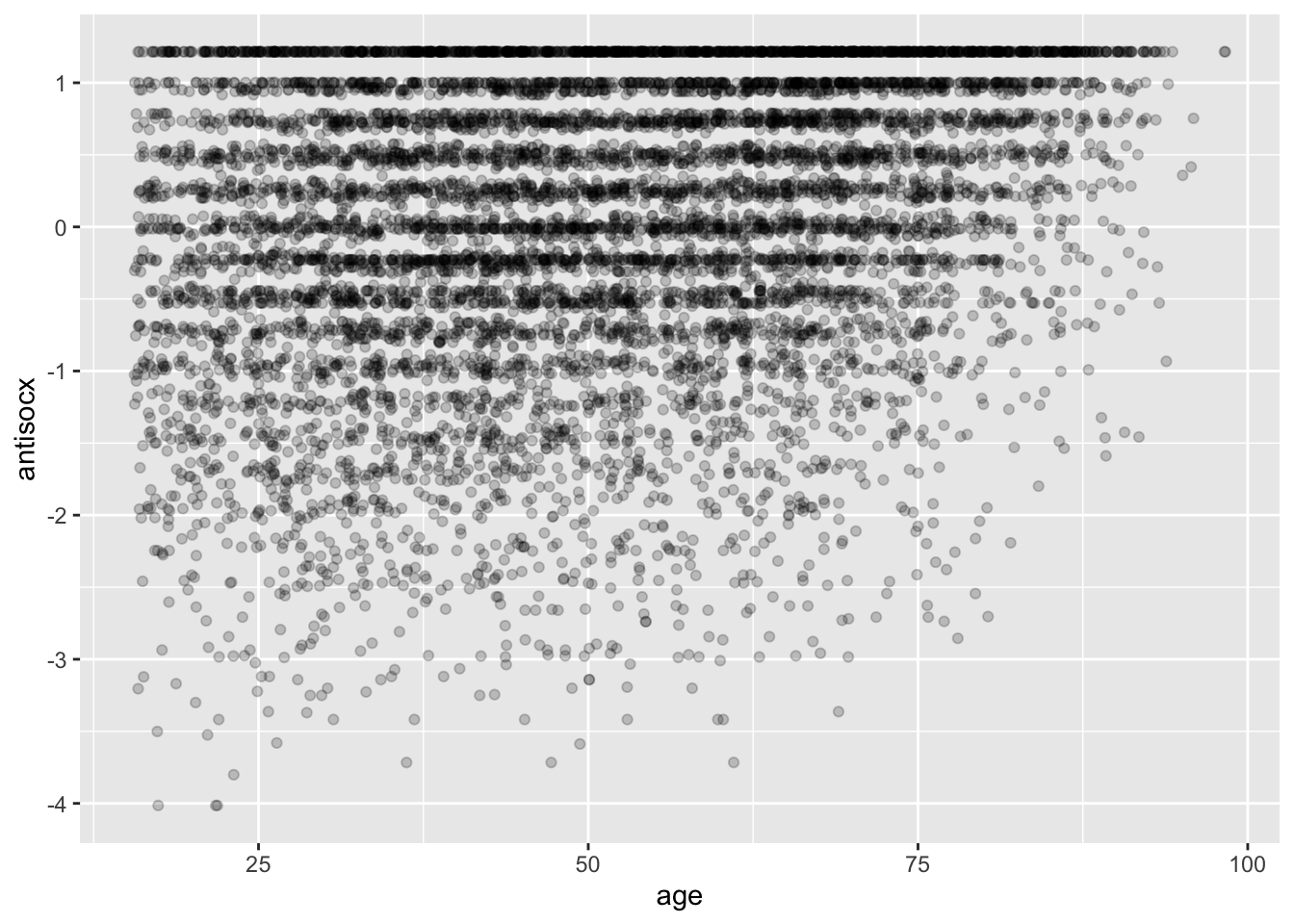
The scatterplot shows how the two variables vary together (covary). Again, you are to guess that random person’s perceived level of antisocial behaviour in the neighbourhood, but, this time, you learn random-person-from-the-sample is 30 years old. What would your answer be now?
Before, we based our guess on descriptive measures of central tendency and dispersion, which included all ages in the sample. Now, we are asked to guess knowing that Random Person is aged 30. This time, we would try and guess the mean of all those who also are aged 30. This is what is known as the conditional mean – the mean of \(Y\) for each value of \(X\).
We now draw a trend line through the scatterplot, which represents the mean of the variable antisocx (on the y-axis) for each age:
ggplot() +
geom_point(data=df, aes(x = age, y = antisocx), alpha=.2) +
geom_line(data=df, aes(x = age, y = antisocx), stat='summary', fun.y=mean,
color="blue", size=1) ## No summary function supplied, defaulting to `mean_se()`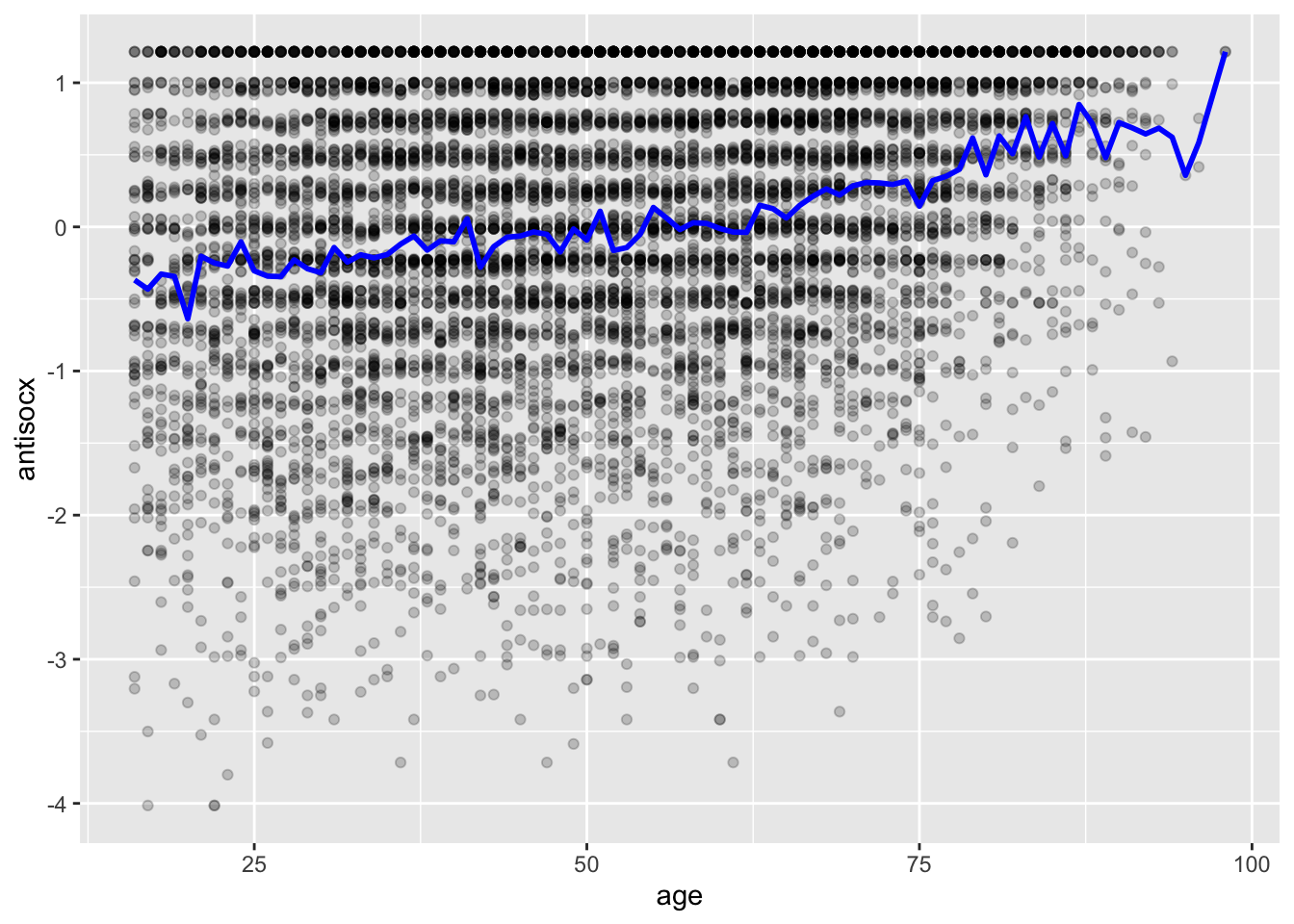
Plotting the conditional means as represented by the blue trend line shows us that the mean of perceived antisocial behaviour for those persons aged 30 is around −0.3. This would be a better guess than the mean for all ages, 0.001823. The trend line gives us a better idea of what is going on in our scatterplot, but the line looks a bit rough. We can make it smoother:
# Make smoother by calculating average perceived antisocial behaviour for age in increments of 5 years
ggplot() +
geom_point(data=df, aes(x = age, y = antisocx), alpha=.2) +
geom_line(data=df, aes(x = round(age/5)*5, y = antisocx), stat='summary', fun.y=mean,color="blue", size=1)## No summary function supplied, defaulting to `mean_se()`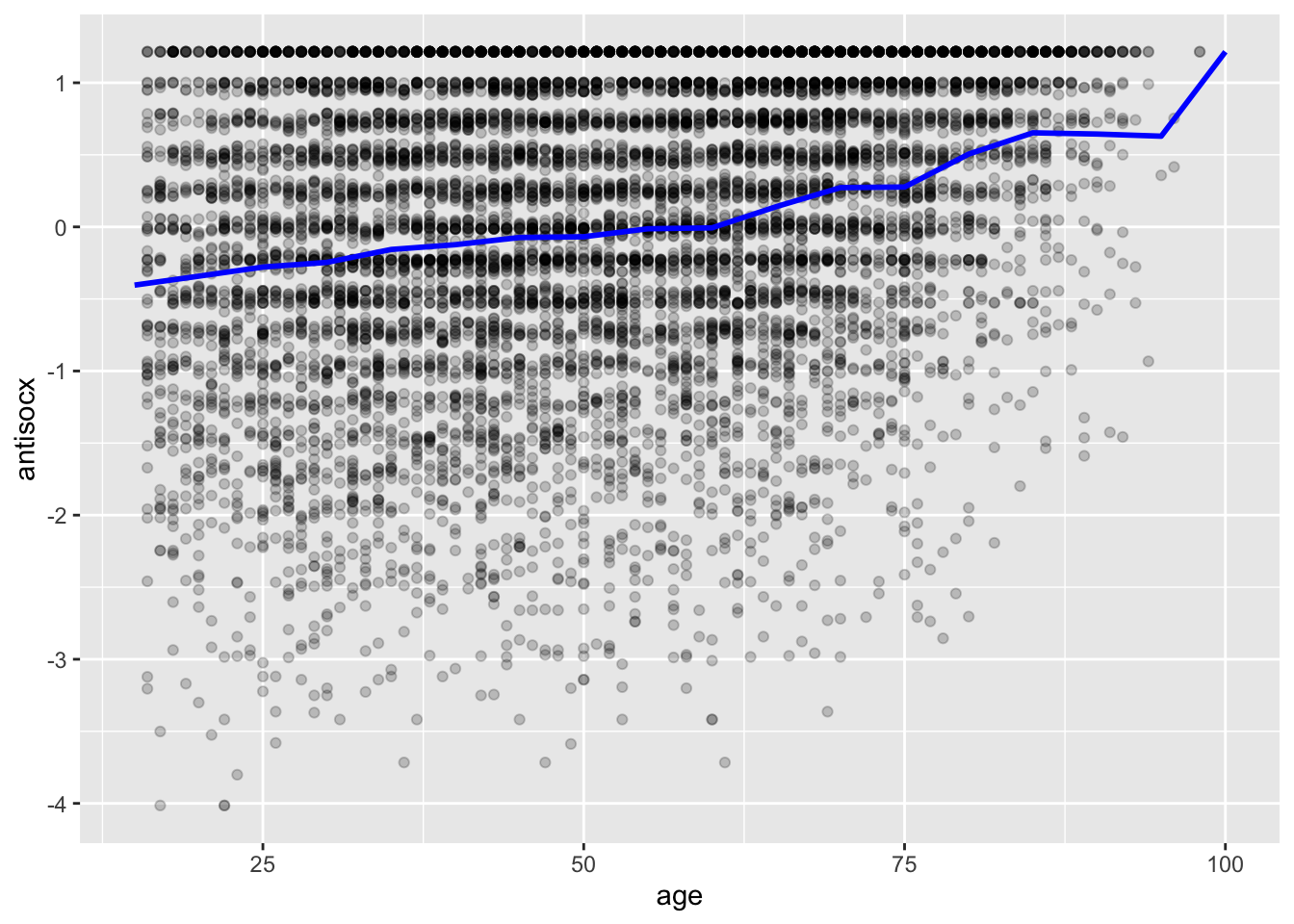
The blue trend line shows us that there is an upward trend, meaning that as age increases, so do levels of perceived neighbourhood antisocial behaviour. Likewise, OLS regression tries to capture the trend or pattern of the data by drawing a straight line of predicted values; this is considered the model of the data:
# method=lm asks for the linear regression line
# se=FALSE asks not to print confidence interval
# Other arguments specify the colour and thickness of the line
ggplot(data = df, aes(x = age, y = antisocx)) +
geom_point(alpha = .2, position = "jitter") +
geom_smooth(method = "lm", se = FALSE, color = "red", size = 1)## `geom_smooth()` using formula 'y ~ x'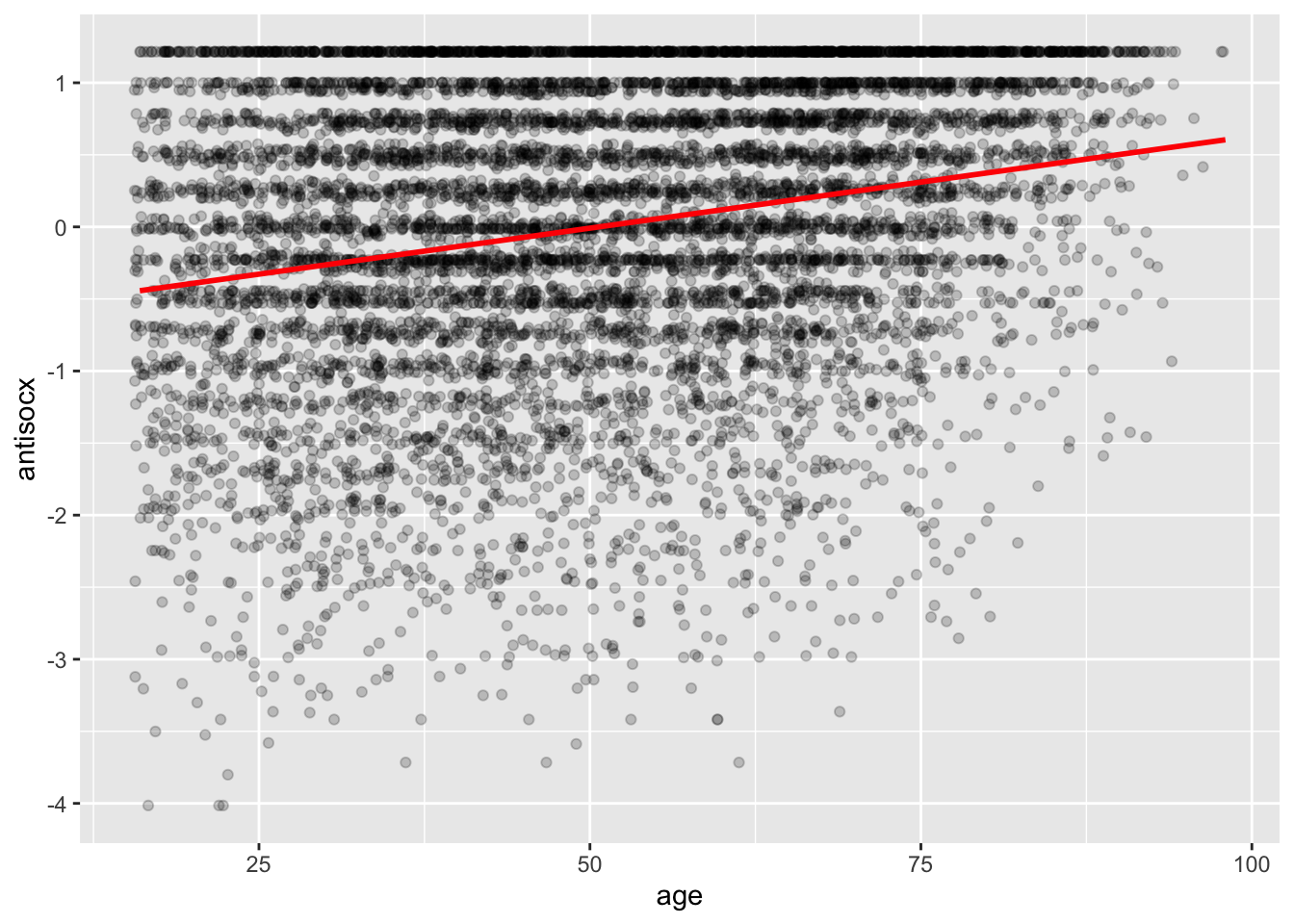
The red regression line produces guesses or predictions for the value of perceived level of antisocial behaviour based on information that we have about age.
The linear line can also be seen as one that tries to summarise the pattern of what is going on among the data points. It does not go through all the points, however, and that means it is not of perfect prediction.
But as Bock et al. (2012) highlight:
‘Like all models of the real world, the line will be wrong – wrong in the sense that it can’t match reality exactly. But it can help us understand how the variables are associated’ (p. 179).
A map is never a perfect representation of the world; the same happens with statistical models. Yet, as with maps, models can be helpful, guiding us to our destination.
Thus, regression can answer questions relating to predictions and does so by drawing a line that tries and capture the overall trend.
9.2.1.5 Activity 5: Regression assumptions
To conduct OLS regression, or linear regression for short, a number of assumptions must be met, so you will need to test for them. Failure to do so will likely result in an incorrect model and drawing conclusions from it would be silly. We only, however, briefly go through the first four assumptions because going into detail is beyond the scope of this class.
The fifth assumption, the assumption of linearity, is an exception. Going into detail about it will give you a better understanding of OLS regression and how it operates.
We now go through each of the five assumptions of OLS regression before conducting it.
Assumption 1: Independence of errors
Errors of the prediction, which make up the regression line, are assumed to be independent of each other. The term heteroscedasticity is used to describe this violation of independence of errors. When we violate this assumption, our points in the scatterplot resemble the shape of a funnel. If there is dependency between the observations, you would need to use other models that are not covered in this class.
Assumption 2: Equal Variances of errors
If the variance of our residuals (and what they are is explained later) is unequal, we will need different estimation methods, but this issue is minor. The reason it is a minor issue is that regression is considered a robust estimation, meaning that it is not too sensitive to changes in the variance.
Assumption 3: Normality of errors
Residuals are assumed to be normally distributed. Gelman and Hill (2007) believe this to be the least important of the assumptions because regression inferences tend to be robust regarding non-normality of the errors. Your results, however, may be sensitive to large outliers, so you will need to drop them if appropriate.
Assumption 4: Multicollinearity
When you are including more than one IV, multicollinearity may be a concern. Independent variables that are highly correlated with each other mean that they are tapping into the same construct. For example, if you include two IVs, parental attachment and parental discipline, you may find that they are highly related to each other because both measure a similar idea - parenting practices perhaps.
One indication of multicollinearity is that if you run a Pearson’s correlation (see Lesson 8, section 8.2.1.2) for the two IVs and get a value above 0.6, you should start investigating further.
Another way to check for multicollinearity is through the variance inflation factor (VIF). How high the VIF should be before multicollinearity is a concern is debatable: here, anything above 5 should be a matter of concern. With this analysis, IVs should be numeric. We include an additional covariate, confidence in the police (confx), to illustrate. The VIF for our variables is conducted with the vif () function in the car package:
# Inputting our variables of interest in a model and placing in object called 'cal_vif'
cal_vif <- lm(antisocx ~ age + confx, data = df)
# Running VIF analysis
vif(cal_vif)## age confx
## 1.003988 1.003988The VIF values are below 5 and indicate that including both variables, age and confx, in the same model does not pose any multicollinearity concerns.
Assumption 5: Linearity
Similar to Pearson’s correlation, a linear relationship must be established before conducting the analysis. If the relationship is non-linear, your predicted values will be wrong, and it will systematically miss the true pattern of the mean of \(Y\). We will learn how to check for this when looking at the residuals from the regression.
9.2.2 Interpreting OLS Regression
In this section, we learn how to interpret bivariate and multiple regression output. Now that we know what the regression line is, how do we draw one? Two points are needed to do so:
We need to know where the line begins. The intercept is where it begins, which is the value of \(Y\), our DV, when \(X\) (our IV) is 0.
We also need to know the angle of that line. This is referred to as the slope.
This translates into the equation:
\[y = b_0 + b_1x_i\]
Where \(b_0\) is the y-intercept and \(b_1x_i\) is the slope of the line. Linear regression models try to find a line that best fits the data points and has the least error. It does so by minimising the distance from every point in the scatterplot to the regression line. This is called least squares estimation and is its hallmark. The farther these points are from the regression line, the more error your regression model will have.
It is not unusual to observe that some points will fall above the line (a positive error value), while other points will fall below it (a negative error value). If we wanted to sum these error values, the problem is that the positive values would cancel out the negative values, underreporting our overall error. This would then incorrectly suggest that our regression line was perfect.
To resolve this issue, the error values are squared before they are summed. This is called the error sum of squares. Our regression model is actually trying to find a line of best fit that has the least (squared) error. Hence, least squared estimation.
9.2.2.1 Activity 6: Bivariate Regression
To fit the regression model, we use the lm() function using the formula specification (Y ~ X):
# Placing model into an object called 'fit_1'
fit_1 <- lm(antisocx ~ age, data = df)
# Get to know the model object
class(fit_1)## [1] "lm"attributes(fit_1)## $names
## [1] "coefficients" "residuals" "effects" "rank"
## [5] "fitted.values" "assign" "qr" "df.residual"
## [9] "xlevels" "call" "terms" "model"
##
## $class
## [1] "lm"summary(fit_1)##
## Call:
## lm(formula = antisocx ~ age, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.8481 -0.5752 0.1297 0.7691 1.6581
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.647232 0.030455 -21.25 <0.0000000000000002
## age 0.012773 0.000563 22.68 <0.0000000000000002
##
## Residual standard error: 0.9705 on 8648 degrees of freedom
## Multiple R-squared: 0.05616, Adjusted R-squared: 0.05606
## F-statistic: 514.6 on 1 and 8648 DF, p-value: < 0.00000000000000022# A more concise display of results is using ‘display()’ from arm package:
display(fit_1)## lm(formula = antisocx ~ age, data = df)
## coef.est coef.se
## (Intercept) -0.65 0.03
## age 0.01 0.00
## ---
## n = 8650, k = 2
## residual sd = 0.97, R-Squared = 0.06We then interpret the regression output. There are several points to focus on when communicating your results:
Beta (or regression) coefficient: this is the value that measures the impact of \(X\) (IV) on \(Y\) (DV). It is the \(b_1\) regression coefficient from the previous equation, the value that will shape the slope for this model. From our output, this value is 0.012773. When the value is positive, it tells us that for every 1 unit increase in \(X\), there is a \(b_1\) increase on \(Y\); if, however, the coefficient is negative, then it represents a decrease on \(Y\). Here, we interpret the result as: ‘For every 1 year older, there is a 0.01 unit increase in level of perceived antisocial behaviour in the neighbourhood.’ The coefficient can be interpreted as a measure of the effect size of this relationship. In addition, with very large sample sizes, you should place less of an emphasis on p-values and more emphasis on the size of the beta coefficients because p-values are sensitive to sample size. For example, you may have all statistically significant covariates, even though the variables have small coefficients. This means that they do not have much of an effect on the DV.
P-value: The p-value for each beta coefficient tests the null hypothesis that the coefficient is equal to zero. A low p-value (\(\alpha\) < 0.05) means you can reject the null hypothesis and that changes in the predictor’s (\(X\)) value are significantly related to changes in the \(Y\) value. For statistically non-significant coefficients, it is not recommended that you interpret them; you can, however, make statements about their general trend (positive or negative). In our output, the p-value is very small ( p < .001). We conclude that age significantly predicts level of perceived antisocial behaviour and that we can reject the null hypothesis.
F-statistic: There is another p-value at the bottom of your regression output and belongs to the F-statistic. This assesses whether our overall model can predict \(Y\) with high confidence, especially if we have multiple predictors. This, too, is statistically significant, meaning that at least one of our IVs must be related to our DV.
(Multiple) \(R^2\): This is known as the percent of variance explained, and it is a measure of the strength of our model. This value ranges from 0 to 1. Towards 1, the better we are able to account for variation in our outcome \(Y\) with our IV(s). In other words, the stronger the relationship is between \(Y\) and \(X\). Weisburd and Britt (2009: 437) suggest that, in criminal justice research, values greater than .40 are rare, but if we obtain such a value, it is considered a powerful model. If the value is lower than .20, the model is considered relatively weak. The output shows that \(R^2\) for our model is about .06 (the multiple r-squared value). We interpret this as our model explains 6% of the variance in the level of perceived antisocial behaviour.
9.2.2.2 Activity 7: Residuals
In the output above we saw something called residuals. The residuals are the differences between the observed values of \(Y\) for each observation minus the predicted or expected values of \(Y\). In other words the distances between each point in the dataset and the regression line (see Figure 9.3).
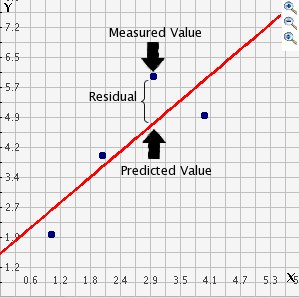
Figure 9.3 Residuals
Figure 9.3 shows the regression line, which is our predicted values, and then the black dots are the actual observed values. The distance between them is essentially the amount by which we were wrong, and all these distances between observed and predicted values are our residuals. Earlier, we were introduced to least squared estimation, and it essentially aims to reduce the average of the squares of all these distances: that is how it draws the line.
Why do we have residuals? The fact that the line is not a perfect representation of the many points makes sense. You cannot predict perfectly what the value of \(Y\) is for every observation only by looking at its level of \(X\). Other relevant factors may not be taken into account by our model to predict the values of \(Y\). And then, of course, we have measurement error and other forms of noise. For example, if we use relative deprivation (\(X\)) to predict homicide (\(Y\)), residuals are inevitable because relative deprivation is not the only factor that can predict homicide – the distance reflects the predictive limitations of that particular model. In other words, how much variation is unexplained.
The regression line aims to improve that prediction. By knowing the values of \(X\), we can build a regression line that aims to get us closer to the actual values of \(Y\) (Figure 9.4). A good model tries to maximise explained variation and minimise the magnitude of the residuals.
We revise our regression equation to represent each value of \(Y\) (rather than the predicted value of \(Y\)) that takes into account residuals:
\(y = b_0 + b_1x + e\)
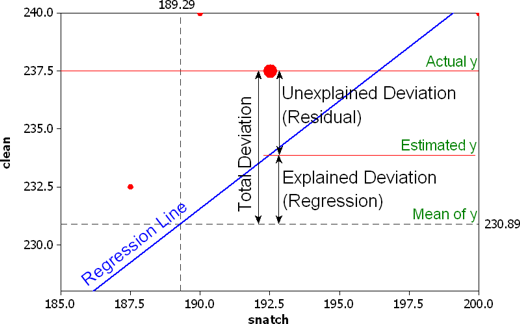
Figure 9.4 R-squared
We can use information from the residuals to produce a measure of effect size, of how good our model is in predicting variation in our dependent variable. This is \(R^2\).
Recall Activity 3 where we tried to guess levels of perceived antisocial behaviour. If we did not have any information about \(X\), which was age, our best bet for \(Y\) would be the mean value of \(Y\).
The distance (squared differences) between that mean value of \(Y\) and the observed values of \(Y\) is what we call the total variation (total deviation in Figure 9.4). Total variation comprises two parts: explained and unexplained variation.
Explained variation is the the distance (again, squared differences) between the regression line and the mean value of \(Y\); this part is predictable from \(X\). In contrast, unexplained variation are the residuals, which is the distance between the regression line and the observed values of \(Y\).
To produce \(R^2\), we would contrast total variation and explained variation. The formula is as follows:
\(R^2 = \dfrac{SSR}{SST} = \dfrac{\Sigma(\hat y_i - \bar y )^2}{\Sigma(y_i - \bar y )^2}\)
Whereby SSR is sum of squares regression and SST is sum of squares total. All this formula is doing is taking a ratio of the explained variation (SSR) by the total variation (SST). This gives us a measure of the percentage of variation in \(Y\) that is ‘explained’ by \(X\).
9.2.2.3 Activity 8: Multiple Regression
At the start of the session, there was mention of one of the major drawbacks of looking at only bivariate relationships: these analyses did not consider other possible explanations.
It could be that you have a statistically significant relationship, but without considering other variables that may explain this relationship, your significant result could, in fact, be spurious – an association that should not be taken very seriously. For some ridiculous examples, click here.
Multiple regression is a way for assessing the relevance of competing explanations. For example, we think there is a relationship between age and perceived antisocial behaviour levels, but we have not considered whether other reasons may provide a better explanation for these perceptions. Maybe previous victimisation or fear of crime may be better contenders.
The equation for multiple regression is similar to bivariate regression except it includes more coefficients:
\[y = b_0 + b_1x_i + b_2x_{ii} +... b_nx_n + e\]
For this example, we include additional variables to our model: sex (sex), previous victimisation in past 12 months (bcsvictim), and confidence in the police (confx). First, we check out these variables and tidy them as necessary:
# Checking out class of variables
class(df$confx) ## [1] "numeric"class(df$bcsvictim)## [1] "numeric"# attach labels to bcsvictim and make ordering false
df$bcsvictim <- factor(df$bcsvictim, labels = c("not victim", "Yes victim"), ordered = FALSE)
# Sex
class(df$sex)## [1] "numeric"table(df$sex)##
## 1 2
## 4064 4586# Recode sex as dummy variable (0 and 1) where female is 0 and ordered is false
df$gender <- recode(df$sex, `1` = 1, `2` = 0)NOTE: you may see an error with the recode() function here. This is because, although we are hoping to call the recode() function which lives inside the dplyr package (which we loaded in the tidyverse bundle), if the most recent package you loaded was car, well there is also a recode() function in the car package.
If you come across this error, you can specify exactly which packge you want to draw the function from, by specifying the pacakge name with :: appended before the function name. So dplyr::recode() instead of recode(). Like so:
df$gender <- dplyr::recode(df$sex, `1` = 1, `2` = 0)Now you can create also a gender variable where we recode to “female” and “male”:
# Change to factor
df$gender <- factor(df$gender, labels = c("female", "male"), ordered = FALSE)
# Double check values match original variable
table(df$gender)##
## female male
## 4586 4064Multiple regression is one way of checking the relevance of competing explanations. You could set up a regression model where you try to predict crime levels with a variable measuring broken windows and a variable measuring structural disadvantage. If, after controlling or adjusting for structural disadvantage, you see that the regression coefficient for broken windows is still statistically significant, you may be onto something, particularly if the estimated effect is still large.
If, however, the regression coefficient of your broken windows variable is no longer significant, then you may be tempted to think that perhaps opponents of Broken Windows Theory (Lesson 7, section 7.2.3.1) were onto something.
It could not be any easier to fit a multiple regression model. You simply modify the formula in the lm() function by adding the additional variables, separated with a +. Let us run this to predict antisocial behaviour with all our independent variables:
# Placing multiple regression into object called 'fit_2'
fit_2 <- lm(antisocx ~ age + gender + bcsvictim + confx, data = df)
# Running the multiple regression
summary(fit_2)##
## Call:
## lm(formula = antisocx ~ age + gender + bcsvictim + confx, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.8854 -0.5684 0.1142 0.7195 2.5249
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.5136682 0.0328072 -15.657 < 0.0000000000000002
## age 0.0104148 0.0005699 18.276 < 0.0000000000000002
## gendermale 0.1003834 0.0207701 4.833 0.00000137
## bcsvictimYes victim -0.4310943 0.0290209 -14.855 < 0.0000000000000002
## confx 0.2038268 0.0106002 19.229 < 0.0000000000000002
##
## Residual standard error: 0.9361 on 8151 degrees of freedom
## (494 observations deleted due to missingness)
## Multiple R-squared: 0.1247, Adjusted R-squared: 0.1243
## F-statistic: 290.3 on 4 and 8151 DF, p-value: < 0.00000000000000022We return to those four points to focus on when confronted with a regression output:
Beta coefficients: The usual interpretation is to state that \(Y\) changes for every one-unit increase in \(X\) when the other variables in the model are held constant (or are ‘controlled for’). Therefore, a 0.01 increase in level of perceived antisocial behaviour in the neighbourhood is associated with a one-year increase in age, for example. This is similar to the bivariate regression. For categorical variables, however, the interpretation is different. Notice how these variables have an additional label attached to them in the output. For example,
genderincludes ‘male’ andbcsvictimincludes ‘yes victim’. Labels that do not appear next to the name of the categorical variable in the model are called the reference category. This category is the lowest value. You can select your reference category based on the modal category or if it is a category in which you are least interested by recoding the variable. We interpret them as the following: males have a perceived antisocial behaviour level that averages 0.10 units higher than that of females; victims have a perceived antisocial behaviour level that averages .43 units lower than that of non-victims. A one-point score increase for confidence in neighbourhood police is related to a .20 increase in level of perceived antisocial behaviour. For each interpretation, covariates in the model are controlled for.P-value: All coefficients are statistically significant, meaning that we can reject the null hypothesis that no differences exist on perceived antisocial behaviour.
F-statistic: Now that we have more than one IV in our model, we evaluate whether all of the regression coefficients are zero. The F-statistic is below the conventional significance level of \(\alpha\) = 0.05, so at least one of our IVs is related to our DV. You will also notice t-values for each IV. These are testing whether each of the IVs is associated with the DV when controlling for covariates in the model.
(Multiple) \(R^2\): The \(R^2\) is higher than that of our previous bivariate regression model. It will, however, inevitably increase whenever new variables are added to the model, regardless if they are only weakly related to the DV. Having said this, the new \(R^2\) value suggests that the addition of the three new variables improves our previous model.
9.2.2.4 Activity 9: Presenting the results
If you would like to professionally present your results, you can use the function tab_model() from the sjPlot package:
tab_model(fit_2)| antisocx | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | -0.51 | -0.58 – -0.45 | <0.001 |
| age | 0.01 | 0.01 – 0.01 | <0.001 |
| gender [male] | 0.10 | 0.06 – 0.14 | <0.001 |
| bcsvictim [Yes victim] | -0.43 | -0.49 – -0.37 | <0.001 |
| confx | 0.20 | 0.18 – 0.22 | <0.001 |
| Observations | 8156 | ||
| R2 / R2 adjusted | 0.125 / 0.124 | ||
# Change name of DV
tab_model(fit_2, dv.labels = "Perceived Antisocial Behaviour")| Perceived Antisocial Behaviour | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | -0.51 | -0.58 – -0.45 | <0.001 |
| age | 0.01 | 0.01 – 0.01 | <0.001 |
| gender [male] | 0.10 | 0.06 – 0.14 | <0.001 |
| bcsvictim [Yes victim] | -0.43 | -0.49 – -0.37 | <0.001 |
| confx | 0.20 | 0.18 – 0.22 | <0.001 |
| Observations | 8156 | ||
| R2 / R2 adjusted | 0.125 / 0.124 | ||
# Change name of IVs
tab_model(fit_2, pred.labels = c("(Intercept)", "Age", "Sex", "Victimisation", "Confidence in Police"), dv.labels = "Perceived Antisocial Behaviour")| Perceived Antisocial Behaviour | |||
|---|---|---|---|
| Predictors | Estimates | CI | p |
| (Intercept) | -0.51 | -0.58 – -0.45 | <0.001 |
| Age | 0.01 | 0.01 – 0.01 | <0.001 |
| Sex | 0.10 | 0.06 – 0.14 | <0.001 |
| Victimisation | -0.43 | -0.49 – -0.37 | <0.001 |
| Confidence in Police | 0.20 | 0.18 – 0.22 | <0.001 |
| Observations | 8156 | ||
| R2 / R2 adjusted | 0.125 / 0.124 | ||
You may also like to present your results visually with a plot. For this, you can use the plot_model() function of the sjPlot package, which makes it easier to produce these sorts of plots. You can find a more detailed tutorial about this function here.
plot_model(fit_2)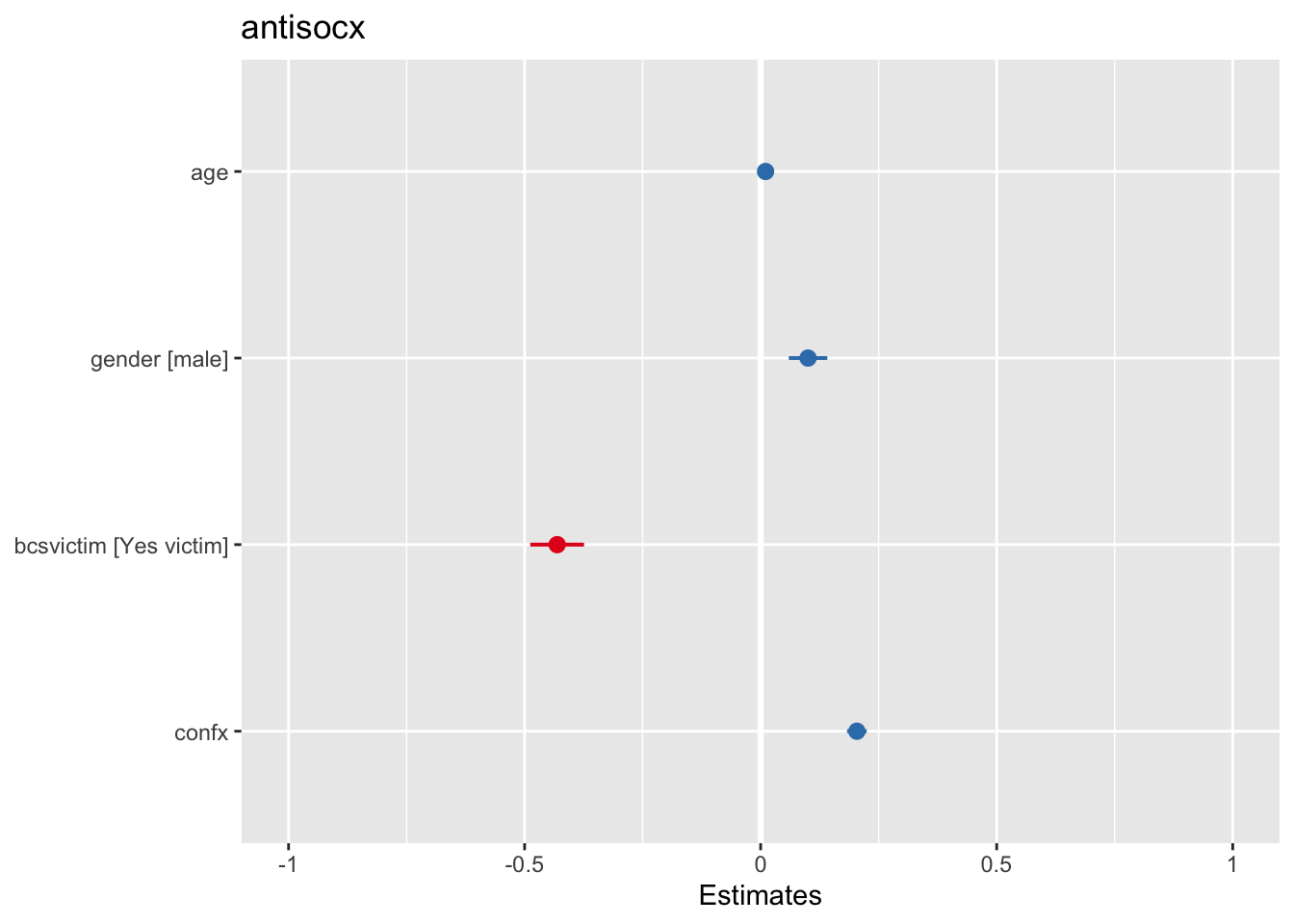
What you see plotted is the point estimates (the circles), the confidence intervals around those estimates (the tiny ‘whiskers’- the longer the line, the less precise the estimate), and the colours represent whether the effect is negative (red) or positive (blue).
There are other packages that also provide similar functionality, like the dotwhisker package that you may want to explore. (More details here.)
9.2.3 Logistic Regression
What if our dependent variable (DV) is categorical and binary? This is where logistic regression, a technique belonging to a family of techniques called generalized linear models, is appropriate. Those assumptions of linearity and normality are not issues because this technique is not based on the normal distribution.
In criminology, it is often the case that our DV has only two categories. For example, victim or not a victim; arrested or not arrested; crime or no crime. This form of regression models the probability of belonging to one of the levels of the binary outcome.
For this example, we are interested in the relationship between race and receiving harsher treatment for possession of marijuana. We use the dataset Arrests from the effects package. This data includes information on police treatment of individuals arrested for possession of marijuana in Toronto, Canada.
Our DV is whether the arrestee was released with summons; if they were not, they received harsh treatment such as being brought to the police station or held for bail:
data(Arrests, package="effects") # It will tell you that the dataset are not found, but it is there
# Checking out our DV
table(Arrests$released)##
## No Yes
## 892 4334# Checking out the order of the levels in the DV
attributes(Arrests$released)## $levels
## [1] "No" "Yes"
##
## $class
## [1] "factor"
9.2.3.1 Activity 10: Preparing your dependent variable
Logistic regression will predict probabilities associated with the level whose first letter is further in the alphabet — this would be ‘yes’, the respondent was released with a summons. But this is not our level of interest. We will need to reorder the levels in the DV using the relevel function:
# Reverse the order
#Rename the levels so that it is clear we now mean 'yes' to harsh treatment
Arrests$harsher <- relevel(Arrests$released, "Yes")
Arrests$harsher <- factor(Arrests$harsher, labels = c("No", "Yes"), ordered = TRUE)
# Check that it matches the original variable ‘released’ but in reverse order
table(Arrests$harsher)##
## No Yes
## 4334 892table(Arrests$released)##
## No Yes
## 892 4334# We will also reverse the levels in our race variable so that ‘white’ is ‘0’
table(Arrests$colour)##
## Black White
## 1288 3938Arrests$race <- Arrests$colour
Arrests$race <- relevel(Arrests$race, "White")
# Check to see coding has changed
table(Arrests$race)##
## White Black
## 3938 1288
9.2.3.2 Activity 11: Fitting and interpreting a logistic regression model
Now that we have arranged the codes of our variables of interest, we fit the logistic regression model using the glm () function and specify a logit model (family=”binomial”). We include three other variables in the model to see to what extent race seems to matter in harsher police treatment even when we control for or consider sex, employment, and previous police contacts:
fit_3 <- glm(harsher ~ race + checks + sex + employed, data=Arrests, family = "binomial")
summary(fit_3)##
## Call:
## glm(formula = harsher ~ race + checks + sex + employed, family = "binomial",
## data = Arrests)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.5226 -0.6156 -0.4407 -0.3711 2.3449
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -1.90346 0.15999 -11.898 < 0.0000000000000002
## raceBlack 0.49608 0.08264 6.003 0.00000000194
## checks 0.35796 0.02580 13.875 < 0.0000000000000002
## sexMale 0.04215 0.14965 0.282 0.778
## employedYes -0.77973 0.08386 -9.298 < 0.0000000000000002
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 4776.3 on 5225 degrees of freedom
## Residual deviance: 4330.7 on 5221 degrees of freedom
## AIC: 4340.7
##
## Number of Fisher Scoring iterations: 5The output is similar to the one produced for linear regression, although there are some differences such as the Akaike information criterion (AIC) and the z-statistic, which is a similar idea to the t-test in linear regression. The z-statistic is a test of statistical significance and assesses whether each variable in the model is associated with the DV.
All IVs are significantly associated with harsher police treatment except for sex. We see that for every one unit increase in the number of previous police contacts, the log odds of receiving harsher treatment (versus being released on summons) increases by 0.36, adjusting for the other variables in the model.
Observe that categorical variables have a label next to them, too, in the output. For example, sex has ‘male’ next to it; race has ‘black’ next to it; employed has ‘yes’ next to it. These are the categories you are comparing to the reference category (whichever level is coded ‘0’). So, being black increases the log odds of receiving harsh treatment by 0.49 compared to being white, while being employed decreases the log odds of harsh treatment by 0.77 compared to being unemployed.
This is good, but most people find interpreting log odds, well, odd – it is not very intuitive. It is common to use the odds ratio (OR) to interpret logistic regression. We convert these values into ORs:
exp(coef(fit_3))## (Intercept) raceBlack checks sexMale employedYes
## 0.1490516 1.6422658 1.4304108 1.0430528 0.4585312# We can add confidence intervals
exp(cbind(OR = coef(fit_3), confint(fit_3)))## Waiting for profiling to be done...## OR 2.5 % 97.5 %
## (Intercept) 0.1490516 0.1081600 0.2026495
## raceBlack 1.6422658 1.3957633 1.9298763
## checks 1.4304108 1.3601419 1.5049266
## sexMale 1.0430528 0.7830594 1.4090622
## employedYes 0.4585312 0.3892103 0.5407210# Another way of getting the results, which uses less typing, is to use the Logit() function from the lessr package
Logit(harsher ~ checks + colour + sex + employed, data=Arrests, brief=TRUE)##
## Response Variable: harsher
## Predictor Variable 1: checks
## Predictor Variable 2: colour
## Predictor Variable 3: sex
## Predictor Variable 4: employed
##
## Number of cases (rows) of data: 5226
## Number of cases retained for analysis: 5226
##
##
##
## BASIC ANALYSIS
##
## Model Coefficients
##
## Estimate Std Err z-value p-value Lower 95% Upper 95%
## (Intercept) -1.4074 0.1724 -8.162 0.000 -1.7453 -1.0694
## checks 0.3580 0.0258 13.875 0.000 0.3074 0.4085
## colourWhite -0.4961 0.0826 -6.003 0.000 -0.6580 -0.3341
## sexMale 0.0422 0.1496 0.282 0.778 -0.2511 0.3355
## employedYes -0.7797 0.0839 -9.298 0.000 -0.9441 -0.6154
##
##
## Odds ratios and confidence intervals
##
## Odds Ratio Lower 95% Upper 95%
## (Intercept) 0.2448 0.1746 0.3432
## checks 1.4304 1.3599 1.5046
## colourWhite 0.6089 0.5179 0.7160
## sexMale 1.0431 0.7779 1.3986
## employedYes 0.4585 0.3890 0.5404
##
##
## Model Fit
##
## Null deviance: 4776.258 on 5225 degrees of freedom
## Residual deviance: 4330.699 on 5221 degrees of freedom
##
## AIC: 4340.699
##
## Number of iterations to convergence: 5
##
##
##
##
## >>> Note: colour is not a numeric variable.
##
##
##
## >>> Note: sex is not a numeric variable.
##
##
##
## >>> Note: employed is not a numeric variable.
##
## Collinearity
##
##
## >>> No collinearity analysis because not all variables are numeric.If the odds ratio is greater than 1, it indicates that the odds of receiving harsh treatment increases when the independent variable, too, increases. Previous police contacts increase the odds of harsher treatment by 43% and being black increases the odds of harsher treatment by 64% (all the while controlling for covariates in the model). Employment, however, has an odds ratio of 0.45. If the OR is between 0 and 1, it is considered a negative relationship.
Referring to the confidence intervals is also helpful: if 1 is within the interval, the result is statistically non-significant. Take the 95% CI of sex, for example.
For both types of regression, it is inappropriate to make comparisons between IVs. You cannot directly compare the coefficients of one IV to the other, unless they use the same metric. For more ways to interpret ORs in logistic regression, refer to the UCLA Institute for Digital Research and Education
9.2.3.3 Model Fit
Now, how well is the fit of our logistic regression model? In order words, how well does our IVs collectively predict the DV? Recall from OLS regression, we assessed how well our overall model predicts the DV by observing the F-statistic and \(R^2\). This is not the case for logistic regression. The reason is, in our familiar linear regression, we understand residual variation (related to that regression line) through the error sum of squares. In logistic regression, there is not one way to understand residual variation, but several, because of its binary outcome. This results in different ways of understanding model fit: (1) quantitative prediction, focused on how close the prediction is to being correct; (2) qualitative prediction, focused on whether the prediction is correct or incorrect; or (3) both. We go through the first one.
How well is the fit of our logistic regression model? In order words, how well does our IVs collectively predict the DV?
Recall from OLS regression that we assessed how well our overall model predicts the DV by observing the F-statistic and, especially, the \(R^2\). This is not the case for logistic regression. The reason is, in our familiar linear regression, we understand residual variation (related to that regression line) through the error sum of squares.
In logistic regression, there is not one way to understand residual variation, but several, because of its binary outcome. This results in different ways of understanding model fit: (1) quantitative prediction, focused on how close the prediction is to being correct; (2) qualitative prediction, focused on whether the prediction is correct or incorrect; or (3) both. We only go through the first one.
9.2.3.4 Activity 12: Quantitative Prediction
A common measure for evaluating model fit is the deviance, also known as -2LL. It measures how accurate the prediction is by multiplying the log likelihood statistic by -2. This log-likelihood statistic measures how much unexplained variance remains after the model is fitted, whereby larger values reflect poorer fit. Larger values of -2LL, similarly, indicate worse prediction.
The logistic regression model can be estimated using an approach of probability called maximum likelihood estimation, which calculates the probability of obtaining a certain result given the IVs in the model. It does so by minimising that -2LL. This is like what OLS regression does with the error sum of squares – tries to minimise it. Thus, -2LL is to logistic regression as the error sum of squares is to OLS regression.
When we re-run our model, we find that -2LL is in the form of null and residual deviances towards the bottom of the output:
Logit(harsher ~ checks + colour + sex + employed, data=Arrests, brief=TRUE)##
## Response Variable: harsher
## Predictor Variable 1: checks
## Predictor Variable 2: colour
## Predictor Variable 3: sex
## Predictor Variable 4: employed
##
## Number of cases (rows) of data: 5226
## Number of cases retained for analysis: 5226
##
##
##
## BASIC ANALYSIS
##
## Model Coefficients
##
## Estimate Std Err z-value p-value Lower 95% Upper 95%
## (Intercept) -1.4074 0.1724 -8.162 0.000 -1.7453 -1.0694
## checks 0.3580 0.0258 13.875 0.000 0.3074 0.4085
## colourWhite -0.4961 0.0826 -6.003 0.000 -0.6580 -0.3341
## sexMale 0.0422 0.1496 0.282 0.778 -0.2511 0.3355
## employedYes -0.7797 0.0839 -9.298 0.000 -0.9441 -0.6154
##
##
## Odds ratios and confidence intervals
##
## Odds Ratio Lower 95% Upper 95%
## (Intercept) 0.2448 0.1746 0.3432
## checks 1.4304 1.3599 1.5046
## colourWhite 0.6089 0.5179 0.7160
## sexMale 1.0431 0.7779 1.3986
## employedYes 0.4585 0.3890 0.5404
##
##
## Model Fit
##
## Null deviance: 4776.258 on 5225 degrees of freedom
## Residual deviance: 4330.699 on 5221 degrees of freedom
##
## AIC: 4340.699
##
## Number of iterations to convergence: 5
##
##
##
##
## >>> Note: colour is not a numeric variable.
##
##
##
## >>> Note: sex is not a numeric variable.
##
##
##
## >>> Note: employed is not a numeric variable.
##
## Collinearity
##
##
## >>> No collinearity analysis because not all variables are numeric.The null deviance is the value of -2LL for a model without any IVs, whereas the residual deviance is the value of -2LL for our present model. We test to see if the null hypothesis, that the regression coefficients (IVs) equal zero, is true. We do so by calculating the model chi-squared. This is the difference between both deviances:
# All the information we need to calculate the model chi-squared is already in our model object
names(fit_3)## [1] "coefficients" "residuals" "fitted.values"
## [4] "effects" "R" "rank"
## [7] "qr" "family" "linear.predictors"
## [10] "deviance" "aic" "null.deviance"
## [13] "iter" "weights" "prior.weights"
## [16] "df.residual" "df.null" "y"
## [19] "converged" "boundary" "model"
## [22] "call" "formula" "terms"
## [25] "data" "offset" "control"
## [28] "method" "contrasts" "xlevels"# We now calculate said chi-squared by taking the difference of the deviances
with(fit_3, null.deviance - deviance)## [1] 445.5594Our obtained value is: 445.56. We do not know, though, how big or small this value is to determine how predictive our model is. We will need a test of statistical significance:
# Obtaining the p-value
with(fit_3, pchisq(null.deviance - deviance, df.null - df.residual, lower.tail = FALSE))## [1] 3.961177e-95# Incorporating previous calculation of difference between deviances
# df.null - df.residual: calculating the degrees of freedom (should equal the number of IVs in the model)The p-value is smaller than \(\alpha\) = 0.05, so we conclude that our model is a better fit than a model with no IVs (or predictors).
In addition, Professor Scott Menard (2010) suggests calculating the likelihood ratio \(R^2\), also known as the Hosmer/Lemeshow \(R^2\), by taking the difference of the previous deviances and dividing it by the null deviance.
The likelihood ratio \(R^2\) tells you the extent to which including your IVs in your model reduces the variation, or error, as measured by the null deviance. The value can range from 0 to 1, where higher values mean better predictive accuracy:
#Likelihood ratio R2
with(fit_3, (null.deviance - deviance)/null.deviance)## [1] 0.09328629This particular \(R^2\) is considered a ‘pseudo- \(R^2\)’ as it is not the same as the one obtained in OLS/ linear regression. There are many kinds of pseudo ones but Menard recommended the likelihood ratio one because (1) of its conceptual similarity to the \(R^2\) in OLS regression; (2) it is not easily swayed by the base rate (the number of cases that have the charateristic of interest); (3) it is easy to interpret; and (4) it can also be used in other generalised linear models, such as ones with categorical DVs with more than two levels.
9.3 SUMMARY
Regression allows us to look at relationships between variables while including other variables, called covariates, in the model. For OLS regression, assumptions must be met before embarking on fitting this model, and has to do with building the regression line whereby the line starts at the intercept and its angle is determined by the slope. Residuals form the equation to determine the \(R^2\) and is the error of the model. When the DV is binary, logistic regression is appropriate. The odds ratio is an easier way to interpret logistic regression. We assess model fit through quantitative prediction measures of deviance, and it is recommended to use the likelihood ratio \(R^2\) instead of other pseudo \(R^2s\)
Homework time!
9.3.0.1 Additional info: diagnosing violation of assumptions
Although so far we have discussed the practicalities of fitting and interpreting regression models, in practical applications you want to first check your model and proceed from there. There is not much point spending time interpreting your model until you know that the model reasonably fits your data.
In previous data analysis modules we covered assumptions made by various statistical tests. The regression model also makes assumptions of its own. In fact, there are so many that we could spend an entire class discussing them. Gelman and Hill (2007) point out that the most important regression assumptions by decreasing order of importance are:
- Validity. The data should be appropriate for the question that you are trying to answer:
“Optimally, this means that the outcome measure should accurately reflect the phenomenon of interest, the model should include all relevant predictors, and the model should generalize to all cases to which it will be applied… Data used in empirical research rarely meet all (if any) of these criteria precisely. However, keeping these goals in mind can help you be precise about the types of questions you can and cannot answer reliably”
Additiviy and linearity. These are the most important mathematical assumptions of the model. We already talked about additivity in the previous section and discussed how you can include interaction effects in your models if the additivity assumption is violated. We will discuss problems with non-linearities today as well as ways to diagnose and solve this problem. If the relationship is non linear (e.g, it is curvilinear) predicted values will be wrong in a biased manner, meaning that predicted values will systematically miss the true pattern of the mean of y (as related to the x-variables).
Independence of errors. Regression assumes that the errors from the prediction line (or hyperplane) are independent. If there is dependency between the observations (you are assessing change across the same units, working with spatial units, or with units that are somehow grouped such as students from the same class), you may have to use models that are more appropriate (e.g., multilevel models, spatial regression, etc.).
Equal variances of errors. When the variance of the residuals is unequal, you may need different estimation methods. This is, nonetheless, considered a minor issue. There is a small effect on the validity of t-test and F-test results, but generally regression inferences are robust with regard to the variance issue.
Normality of errors. The residuals should be normally distributed. Gelman and Hill (2007: 46) discuss this as the least important of the assumptions and in fact “do not recommend diagnostics of the normality of the regression residuals”. If the errors do not have a normal distribution, it usually is not particularly serious. Regression inferences tend to be robust with respect to normality (or nonnormality of the errors). In practice, the residuals may appear to be nonnormal when the wrong regression equation has been used. So, I will show you how to inspect normality of the residuals not because this is a problem on itself, but because it may be give you further evidence that there is some other problem with the model you are applying to your data.
Apart from this, it is convenient to diagnose multicollinearity (this affects interpretation) and influential observations.
So these are the assumptions of linear regression.
In this section we can go through very quickly how to test for some of them using visuals. While finding that some of the assumptions are violated do not necessarily mean that you have to scrap your model, it is important to use these diagnostics to illustrate that you have considered what the possible issues with your model is, and if you find any serious issues that you address them.
In r, we can use the plot() function on our output lm object to look through some diagnostics. This gives us 4 plots, so to show them all, we’ll use the code par(mfrow = c(2, 2)) to split our plot window into 4 panes (remember to set back, run par(mfrow = c(1, 1))). For example, let’s return to fit_1, our very first model.
par(mfrow = c(2, 2))
plot(fit_1)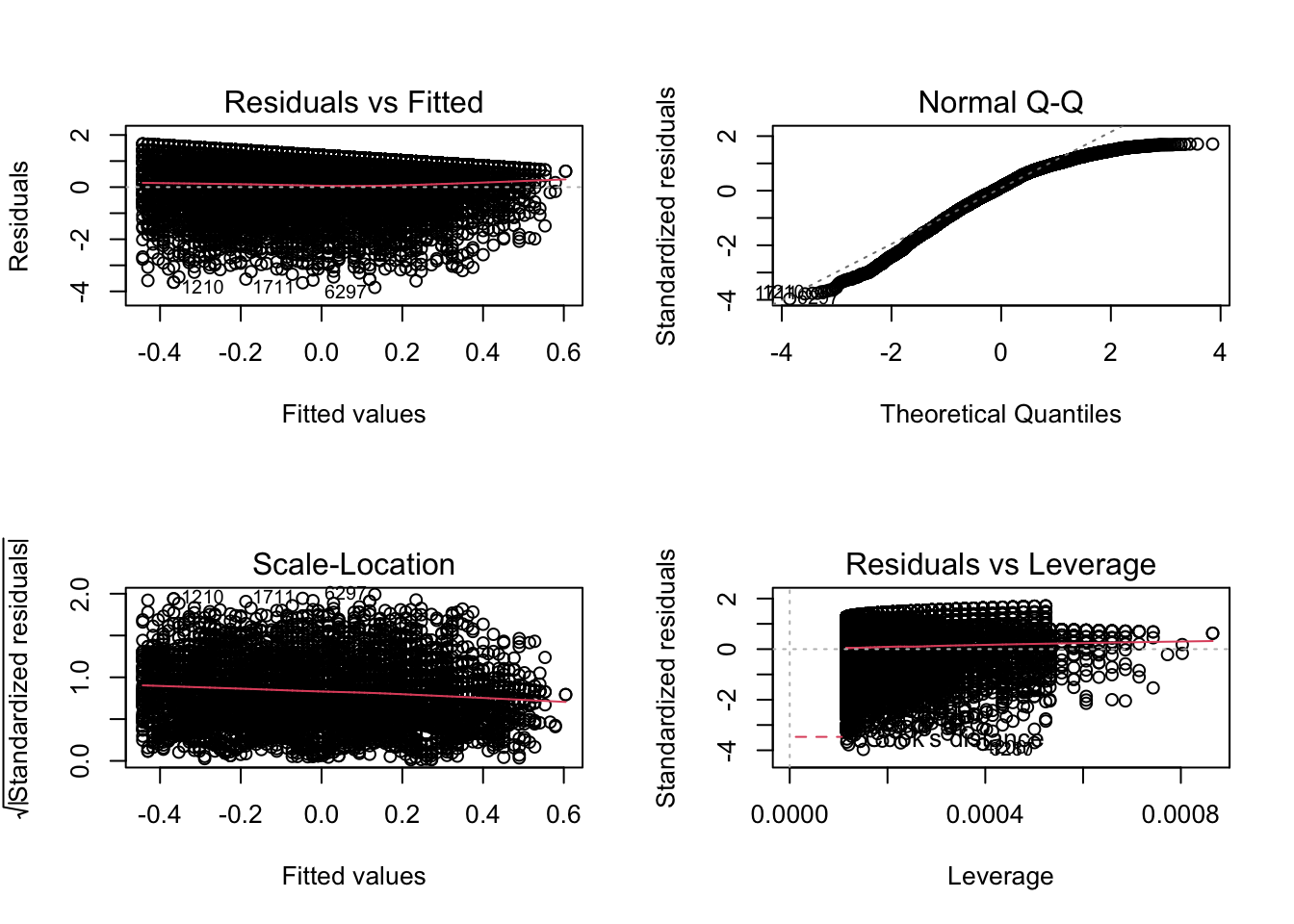
The 4 plots we get are
- Residuals vs Fitted. Used to check the linear relationship assumptions. A horizontal line, without distinct patterns is an indication for a linear relationship, what is good.
- Normal Q-Q. Used to examine whether the residuals are normally distributed. It’s good if residuals points follow the straight dashed line.
- Scale-Location (or Spread-Location). Used to check the homogeneity of variance of the residuals (homoscedasticity). Horizontal line with equally spread points is a good indication of homoscedasticity. This is not the case in our example, where we have a bit of a heteroscedasticity problem (remember funnel-shape from the video!).
- Residuals vs Leverage. Used to identify influential cases, that is extreme values that might influence the regression results when included or excluded from the analysis.
We can also run some tests to confirm what we see in the plots.
For example, to test for heteroskedasticity (unequal variance in our residuals) we can run a Breusch-Pagan test from the lmtest package or a NCV test from the car package.
lmtest::bptest(fit_1) # Breusch-Pagan test##
## studentized Breusch-Pagan test
##
## data: fit_1
## BP = 114.41, df = 1, p-value < 0.00000000000000022car::ncvTest(fit_1) # NCV test## Non-constant Variance Score Test
## Variance formula: ~ fitted.values
## Chisquare = 131.0805, Df = 1, p = < 0.000000000000000222Both these test have a p-value less that a significance level of 0.05, therefore we can reject the null hypothesis that the variance of the residuals is constant and infer that heteroscedasticity is indeed present, thereby confirming our graphical inference.
For testing whether the residuals violate the normality assumption, we can use the Anderson-Darling test for the composite hypothesis of normality with the ad.test() function in the nortest package.
nortest::ad.test(fit_1$residuals)##
## Anderson-Darling normality test
##
## data: fit_1$residuals
## A = 89.77, p-value < 0.00000000000000022=======