Chapter 2 Getting to know your data
Variables, Labels, and Subsetting
Learning Outcomes:
- Create a project in
Rto refer back to for each session - Understand what variables are and how to examine them in
R - Learn how to make new variables
- Learn how to label variables and their values
- Learn how to subset select observations and variables
Today’s Learning Tools:
Total number of activities: 9
Data:
- National Crime Victimization Survey (NCVS)
Packages:
dplyrherehavenlabelledsjlabelled
Functions introduced (and packages to which they belong)
%>%: Known as the pipe operator, and allows users to pass one output of a code to become the input of another (dplyr)as_factor(): Changes the class of an object to factor class (haven)attributes(): Access object attributes, such as value labels (base R)case_when(): Allows users to vectorize multiple if / if else statements (dplyr)count(): Counts the number of occurrences (dplyr)dim(): Returns the number of observations and variables in a data frame (base R)dir.create(): creates a new folder in a project (base R)factor()Creates a factor (base R)filter(): Subsets a data frame to rows when a condition is true (dplyr)get_labels(): Returns value labels of labelled data (sjlabelled)here(): Finds a project’s files based on the current working directory (here)mutate(): Creates new vectors or transforms existing ones (dplyr)names(): Returns the names of the variables in the data frame (base R)read_spss(): Imports SPSS .sav files (haven)recode(): Substitutes old values of a factor or a numeric vector with new ones (dplyr)remove_labels(): Removes value labels from a variable (sjlabelled)remove_var_label(): Removes a variable’s label (labelled)select(): Select columns to retain or drop (dplyr)table(): Generates a frequency table (base R)var_label(): Returns or sets a variable label (labelled)
2.1 The Tidyverse
Last time, we installed our first package, dplyr. This is one of a number of packages from what is known as tidyverse.
Figure 2.1 Tidyverse logo
The tidyverse contains packages that help us carry out wrangling (i.e., cleaning variables), analysis, plotting, and modelling of our data. The ethos of tidyverse is that working and using tidy data makes our lives easier in the long run, allows us to stick to specific conventions, and enables us to share with others who follow this approach. Essentially, tidy data makes data analysis easy to carry out and to communicate to others.
So what is tidy data?

Like what was mentioned in last week’s lesson, our columns represent our variables, but, also, our cases (or better known in the tidyverse as observations) are our rows, whereby each cell is a value of that column’s given variable for the observation in that row.
In this class, we will be working with tidy data. Generally, if you have messy data, which is common in the real world of data analysis, your first task is to wrangle it until it is in a tidy shape similar to the ones described in Figures 2.2 and 2.3.
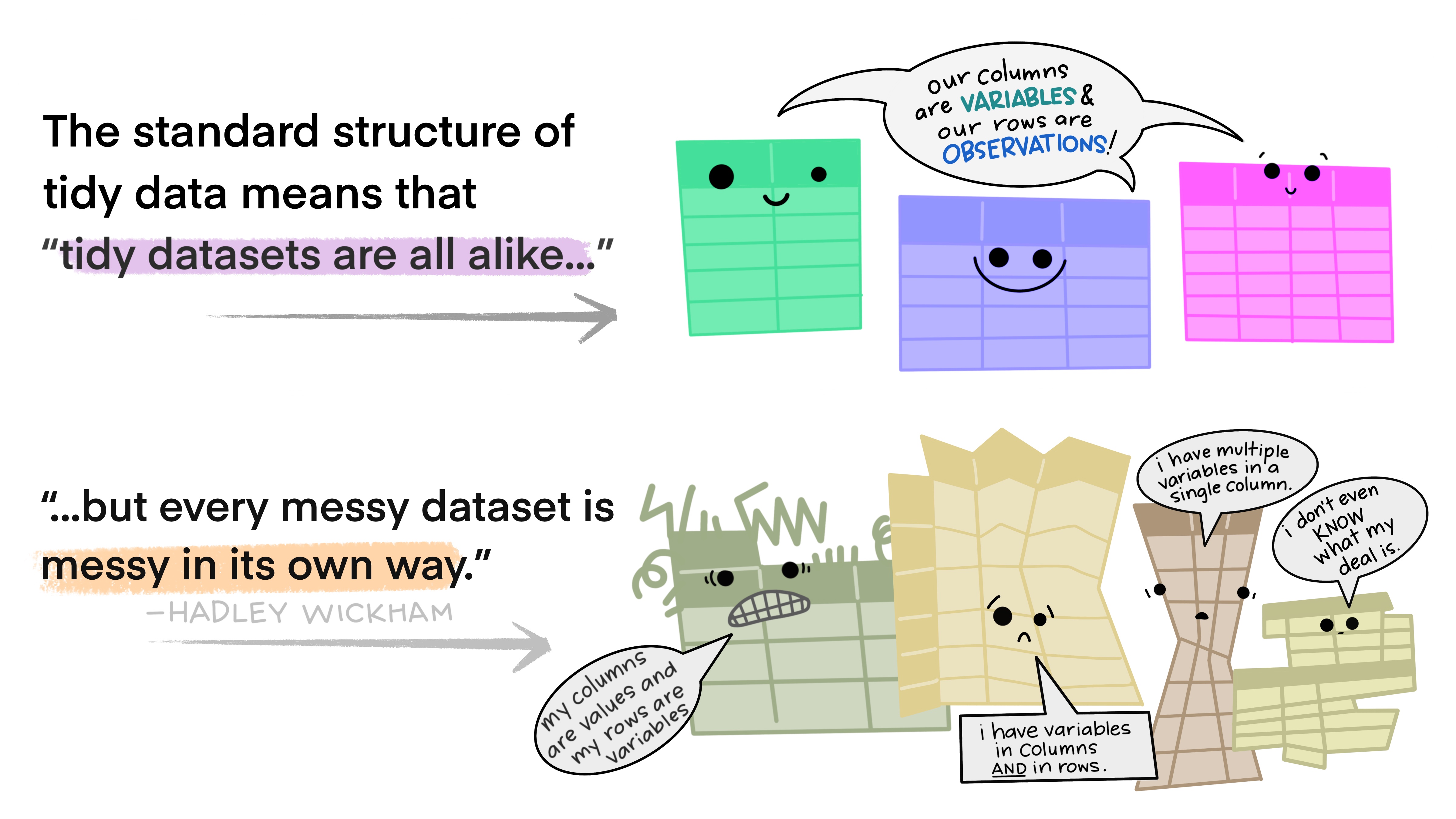
Figure 2.3 Tidy data versus messy data by Alison Horst
In today’s lesson, we use dplyr and other tidyverse packages to explore and get to know our data.
Being familiar with our data requires knowing what they comprise and what form they take. ‘Tidying’ our data through wrangling – labelling, reformatting, recoding, and creating new variables – will help with this step in the data analysis process. Today we will learn another three topics related to tidy data: variables, labels, and subsetting.
Let us get started and load dplyr:
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union# Like last week, you can also check the 'Packages' tab in the 'Files, Plots...' pane to see if the box next to 'dplyr' has been ticked
2.2 R Projects – Getting Your Work Files Organised
Although today is focused on tidy data, it is also helpful if whatever you are working on is also tidy and found in one easily accessible folder. By saving work inside a project, you can find files such as data and scripts related to specific work in a single working directory. Let us get into the habit of doing this:
2.2.1 Activity 1: Making yourself a project
• Click on the top right tab called Project: (None) - Figure 2.4
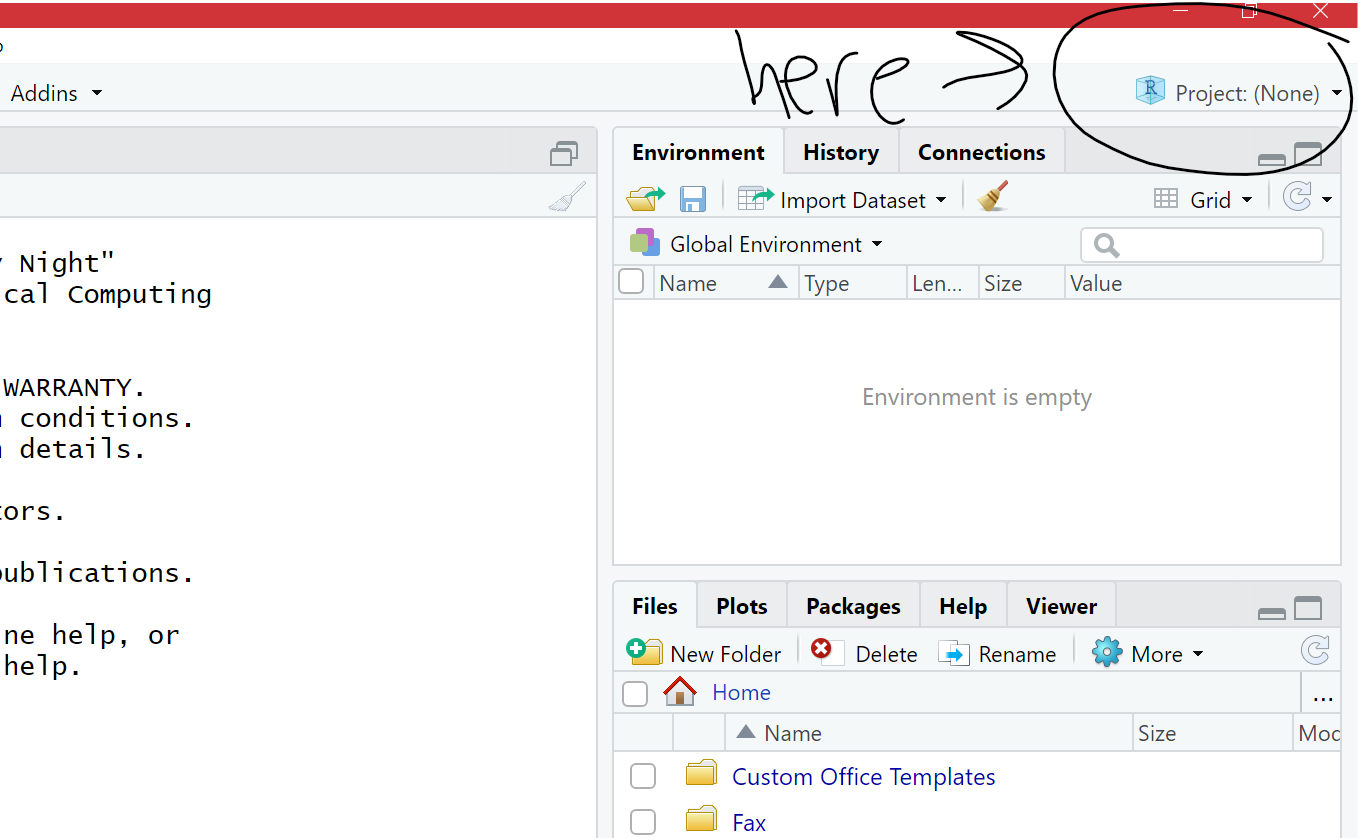
Figure 2.4 Click on Project: (None)
In the options that appear, choose Existing Directory. The reason is you may have already created a folder for this work if you had saved your script from last week and from what you have done so far today. For example, Reka had saved a folder called ‘modelling2021’ with her scripts in it and will have her project in that same place too (see Figures 2.5 and 2.6).
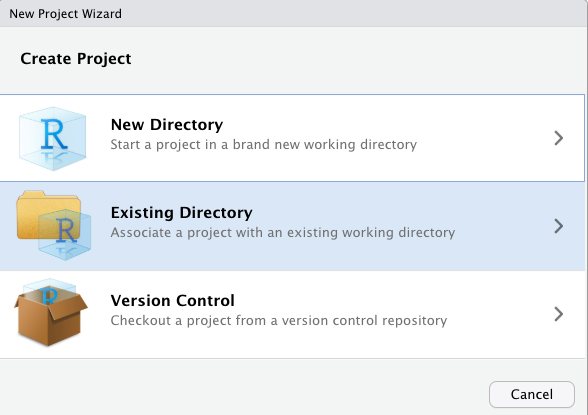
Figure 2.5 Existing directory
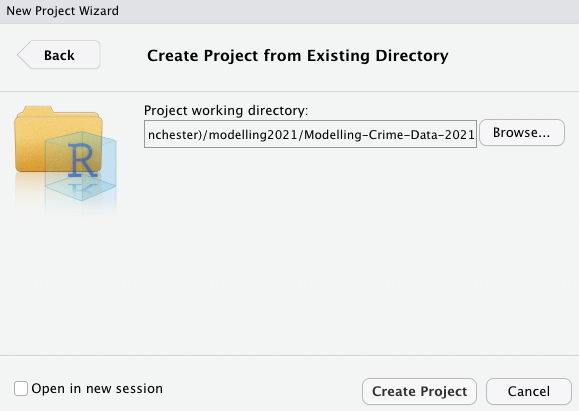
Figure 2.6 Create project from existing directory
Another option appears (Figure 2.6). Use the ‘Browse…’ button to select the folder where you have so far saved your script(s). Once you have done this, click on Create Project and your new project will be launched.
This will now open up a new RStudio window with your project. In the future, you can start right where you left off by double clicking your project, which is a .Rproj file, to open it. It helps if you keep all your work for this class in one place, so R can read everything from that folder.
Now if you did not save any scripts or files thus far, so want to create a project in a new place, you can do the following:
Click on New Project (Figure 2.5). A window with different options appears. Create your project in New Directory and then click New Project
Choose a name for your project (e.g., r_crim_course) and a location (i.e., working directory, which will be explained a little further below) where your project will be created
Inside your project, you can organise it by having separate files: one for scripts, one for data, one for outputs, and another for visuals. You can make these with the function dir.create():
# For example, to make a sub-folder called 'Datasets' in your project folder, type this into your console pane:
dir.create("Datasets")Another example: to create the online tutorial for this class, we have a project called Modelling-Crime-Data-2021. Figure 2.7 shows that this title appears in the top right hand corner and its contents, including sub-folders, appear in under the Files tab in the Files, Plots… pane.
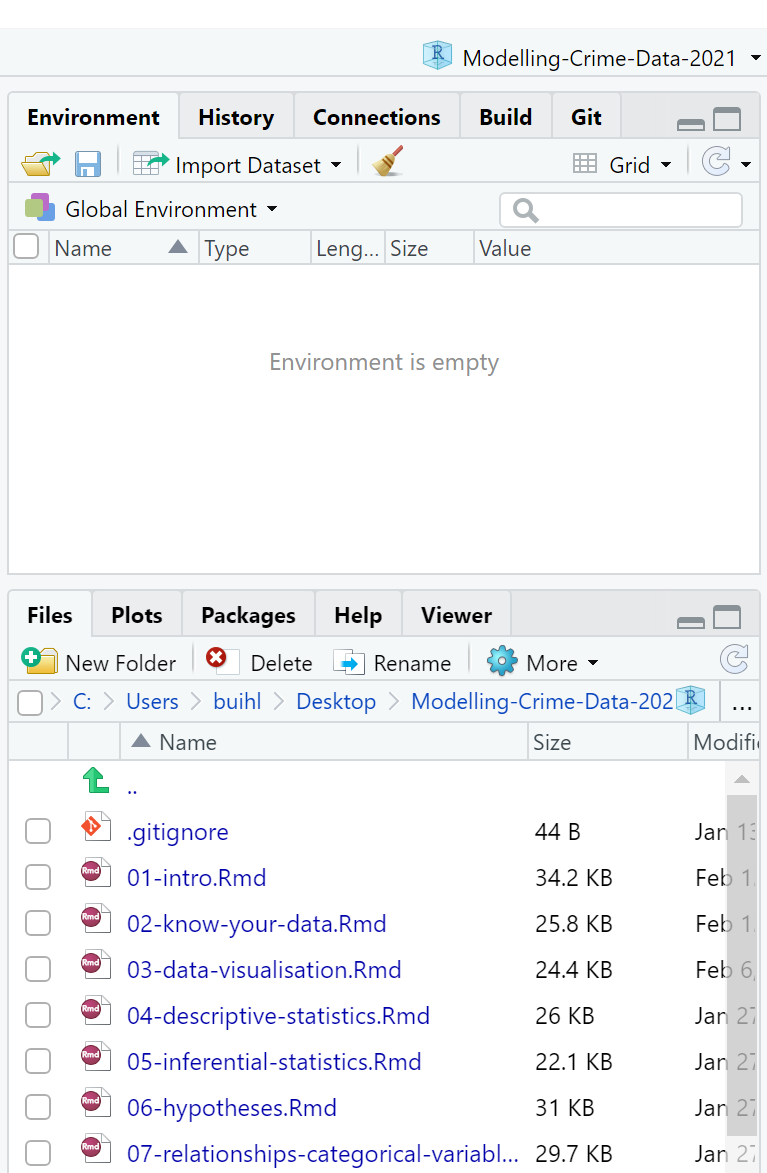
Figure 2.7 How a project appears
The files in your Files, Plots… pane tell you in what folder you are automatically working. This is known as your working directory, the default location that appears when you open RStudio. Wherever your R project (that file ending in .Rproj) is saved will be the working directory.
In your group google sheets, type the name of your R project and in which location it is in. Now decide whether this is a good location for your R project. For example, is the location name too long? (Something like ‘C: Users xx Desktop xx xx Manchester xx xx xx xx xx xx’ is too long and you might run into problems later.) Or are there files that are for your other course units in there too? If doubtful about the location of your project, move it somewhere else you think is more appropriate.
You can read on why projects are useful here: https://www.r-bloggers.com/2020/01/rstudio-projects-and-working-directories-a-beginners-guide/
2.2.1.1 The here package
Whenever you want to locate certain files within your Project, use the here package:
# First, you must install it if you have not done so:
install.packages("here")# Then bring it up with 'library()' because it may not come up automatically after installing it
library(here)## here() starts at /Users/reka/Dropbox (The University of Manchester)/modelling2021/Modelling-Crime-Data-2021Using the here package is better than typing out the exact location of your file, which can be tedious. The next section shows how to use the here() function from said package to import data from the National Crime Victimization Survey (NCVS).
2.3 Importing Data
Here is another tidyverse package to install:
install.packages("haven")library(haven)haven enables R to understand various data formats used by other statistical packages such as SPSS and STATA. We will need this package to open data in its diverse forms. When we worked with Excel last semester in Making Sense of Criminological Data, we could only open certain type of files. With R, we can open a wide range of data files, which opens up many possibilities of analysis for us. Let us give this a try now.
2.3.1 Activity 2: Importing and Viewing Data
Go to the class Blackboard. Then click on Learning materials and then on Week 2 where you will find the dataset ‘NCVS lone offender assaults 1992 to 2013’.
Download the data into the Datasets sub-folder in your working directory you had created using the function dir.create().
This data comes from The National Crime Victimization Survey (NCVS) from the US. You can read more about it here.
Now how to bring this dataset up in RStudio? We must follow these steps to read the data:
- We note what kind of dataset file, ‘NCVS lone offender assaults 1992 to 2013’, is. The extension is
.savand this means that it is a file from the statistical package SPSS, so the function we need isread_spss()from thehavenpackage.
- We note what kind of dataset file, ‘NCVS lone offender assaults 1992 to 2013’, is. The extension is
- When importing data with the
here()function, you must specify where the file is and what it is called in the brackets. In this case, we need to specify that it is in the sub-folder ‘Datasets’ and it is called ‘NCVS lone offender assaults 1992 to 2013.sav’. So, the code to find the file would be:here("Datasets", "NCVS lone offender assaults 1992 to 2013.sav").
- When importing data with the
Completing these steps, we now can load our dataset and place it inside a data frame called ncvs:
# Importing our SPSS dataset and naming it ‘ncvs’
ncvs <- read_spss(here("Datasets", "NCVS lone offender assaults 1992 to 2013.sav"))What you are saying to R is the following:
My data, NCVS lone offender assaults 1992 to 2013, is a .sav file. Therefore, it is an SPSS dataset and is located in the sub-folder called Datasets in my default working directory.
R, please extract it from here, understand it, and place it in a data frame object calledncvs, so I can find it inRStudio.
To view the new data frame, ncvs, type:
View(ncvs)A tab appears labelled ‘ncvs’. In it, you can view all its contents. In your group google sheets, type how many ‘entries’ and ‘columns’ there are in our data frame, ncvs.
There are other ways to load data that are of different formats. For more information, see this cheatsheet for importing data. But for now, you can rely on us showing you the functions you need.
2.4 Today’s 3 (TOPICS)
We now have data to tidy in R, so onto our three main topics for this week: variables, labels, and subsetting.
2.4.1 Variables
Variables can be persons, places, things, or ideas that we are interested in studying. For example, height and favourite football team.
Last week, we learned a little on how to examine what our variables are. Let us revisit this. One of the first things we do to get to know our ncvs data frame is to identify the number of rows and columns by using the function View() as we did above, or, a more direct way, the function dim():
dim(ncvs)## [1] 23969 47Like your answer from Activity 2, the data framencvs has 47 columns, meaning that it has 47 variables. What are these variables all called? We can get their names using the names function:
names(ncvs)## [1] "YEAR" "V2119" "V2129"
## [4] "V3014" "V3016" "V3018"
## [7] "V3021" "V3023" "V3023A"
## [10] "V3024" "V2026" "V4049"
## [13] "V4234" "V4235" "V4236"
## [16] "V4237" "V4237A" "V4238"
## [19] "V4239" "V4240" "V4241"
## [22] "V4242" "V4243" "V4244"
## [25] "V4245" "V4246" "V4246A"
## [28] "V4246B" "V4246C" "V4246E"
## [31] "V4246F" "V4246G" "V4247"
## [34] "V4528" "injured" "privatelocation"
## [37] "reportedtopolice" "weaponpresent" "medicalcarereceived"
## [40] "filter_$" "relationship" "Policereported"
## [43] "victimreported" "thirdpartyreport" "maleoff"
## [46] "age_r" "vic18andover"We observe that a number of these variable names are codes, which is somewhat similar to the Crime Survey of England and Wales (CSEW) data we worked with last semester, whereby the variable polatt7, for example, was trust in police.
You could view the data frame like you did previously (with the function View()) to find out what the variables actually are, or you could look it up in the data dictionary here. The advantage of the data dictionary – which will accompany all well-documented datasets – is it will tell you precisely what the variables are and how they measure their characteristics in that particular dataset. For example, the data dictionary that accompanies the NCVS tells us that the variable V3014 is age.
Measurement
What about the level of measurement for these variables? Different variable types refer to different levels of measurement.
For categorical variables, we can have variables that are nominal (no order), ordinal (have an order), or binary (only two possible options, like ‘yes’ and ‘no’).
Figure 2.8 Categorial variables by Allison Horst
Numeric variables can be classified two separate ways. Last semester, we discussed the difference between interval and ratio variables. Interval variables have the same distance between observations, but have no true zero. The temperature in Celsius is one example. Ratio variables, on the other hand, do have a true zero point. Calculating a ratio from the values of these variables makes sense, but for values from interval variables, it does not. For example, it is pretty meaningless to state that 20 degrees Celsius is twice as hot as 10 degrees Celsius (‘0’ in Celsius is not the absolute lowest temperature). But if Reka has £30 pounds in her bank account and Laura has £60, it is meaningful to say Laura has twice as much savings as Reka does.
Another way to classify numeric variables is to distinguish between discrete and continuous variables. Discrete numeric variables have set values that make sense. For example, crime is one such variable. It is understandable to have 30 burglaries in May and 50 burglaries in December, but it is not understandable to have 45.2482 burglaries. Continuous numeric variables, however, can take on any value between a lower and upper bound and be meaningful. For example, weight and height. Here is an apt illustration:

Figure 2.9 Discrete versus continuous numeric variables by Allison Horst
2.4.1.1 Variables in R
So, how are these levels of measurement among variables relevant in R? Nominal and ordinal variables are encoded as a factor class because they are categorical characteristics, so take on a limited number of values; factors are like the integer vector introduced last week but each integer is a label. Numeric variables, on the other hand, are encoded as a numeric class.
2.4.1.1.1 Activity 3: Identifying a variable’s level of measurement
Identifying the level of measurement should be straightforward when examining each variable. In some cases, however, R may not quite grasp what kind of variable you are working with. Thus, you will need to find out what R thinks your variable is classed as.
How do you ask R what your variable is? Let us find out by using our ncvs data frame.
First, do you remember from last week how to refer to one specific variable in your data frame?
It is: dataframe$variablename
If we want to find out about the variable injured (whether the person was injured or not) from our data frame ncvs, for example, we can refer to the variable specifically. Let us use the attributes() function to examine this variable.
# To see the class of a specific variable, such as the variable ‘injured’, we use:
attributes(ncvs$injured)## $label
## [1] "Victim Sustained Injuries During Vicitmization"
##
## $format.spss
## [1] "F8.2"
##
## $display_width
## [1] 10
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## uninjured injured
## 0 1# The $ symbol allows us to access specific variables in a data frame object
# The $ symbol must be accompanied by the name of the data frame!We can see the label (‘Victim Sustained Injuries During Vicitmization’), and the values (at the bottom) indicating ‘0’ for ‘uninjured’ and ‘1’ for ‘injured’. This appears to be a categorical variable with 2 possible values; therefore, a binary variable.
Now your turn: find out what is the class of the variable weaponpresent. In your googledoc, type out the answer and the code you used to get that answer.
2.4.1.2 Formatting Classes and Value Labels
In some cases, you may want to make changes to how variables are classed. For example, in our data frame nvcs, some of the variables are classed as haven_labelled.
What is this, you ask? When we use the haven() function to import data, R keeps the information associated with that file – specifically the value labels that were in the dataset. In practice, therefore, you can find categorical data in R embedded in very different types of vectors (e.g., character, factor, or haven labelled) depending on decisions taken by whomever created the data frame.
Although we understand why these variables are labelled as haven_labelled, they do not help us understand what class these variables actually are. If we know a variable is classed as factor, We can change it to be so. For example, we want to change the class of variable V3018 to be accurately classed as factor:
# V3018 is a binary variable indicating sex
attributes(ncvs$V3018)## $label
## [1] "SEX (ALLOCATED)"
##
## $format.spss
## [1] "F1.0"
##
## $display_width
## [1] 7
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## Male Female Residue Out of universe
## 1 2 8 9# It is indeed classed as 'haven-labelled'
# Naming the newly created factor 'sex' so we do not erase the original variable
# Specify the order we want our variable labels using 'labels= c()'
ncvs$sex <- factor(ncvs$V3018, labels = c("male", "female"))
table(ncvs$sex)##
## male female
## 12533 11436attributes(ncvs$sex)## $levels
## [1] "male" "female"
##
## $class
## [1] "factor"The new variable, sex, a duplicate of V3018, is no longer a ‘haven_labelled’ type variable. It is now classed as a factor. But remember, ‘class’ and ‘factor’ are R lingo – we would still describe this as a categorical, binary variable! We include R language so that you know what it means and how it links to what you have learned in your data analysis classes.
2.4.1.3 Recoding and Creating New Variables
What if we want to create a new variable? Here are three scenarios where we would want to do so:
Scenario 1: we want a variable like the injured variable, but for the values, we instead want to see ‘uninjured’ and ‘injured’ and not ‘0’ and ‘1’;
Scenario 2: we want a composite variable, like the fear of crime composite variable from last semester that comprised many different scores;
Scenario 3: we want to change an existing variable that is ordinal with four outcomes into a binary variable with only two outcomes.
We address all three scenarios in turn. Recoding and creating new variables is called data wrangling and the package dplyr is most appropriate for doing so.

Figure 2.9 Data wrangling by Allison Horst
2.4.1.4 Activity 4: Creating a new variable by recoding an existing one
For scenario 1, we want to recode our existing injured variable. We view a frequency table of this variable to understand why. The frequency table tells us the number of times each value for the variable occurs. This is similar to the Pivot Table function in Excel from last semester.
In R, the way to create a frequency table for one variable is to use the function table(). Inside the brackets, you would type the data frame and the variable you want to create the frequency table for. We want a frequency table for the injured variable:
table(ncvs$injured)##
## 0 1
## 16160 7809The frequency table shows that 16,160 people answered ‘0’ to the question of whether they were injured, while 7,809 answered ‘1’. Since we ran our attribute() function earlier, we know that ‘0’ means ‘uninjured’, and ‘1’ means ‘injured’. Often in data, ‘0’ represents the absence of the feature being measured and ‘1’ means the presence of such feature.
Although we know what the numbers represent, we might forget or someone else unfamiliar with the data views the variable and may not know what the values mean. In this case, it would be helpful to change the numbers ‘0’ and ‘1’ to what they represent.
To do so, we create a new variable whereby a new column appears in the data frame. It is similar to when you create an object. Remember:
name <- "Reka"The only difference is that we must attach this new object (which appears as a column) to the dataframe, and that the number of things we put in this object needs to match the number of rows in that data frame. As we are creating a new variable from one that already has the same number of rows, this is not an issue.
Let us again create a duplicate variable of the injured variable:
# Create the new variable ‘injured_new’ from ‘injured’
ncvs$injured_new <-ncvs$injured View the ncvs data frame. Notice that a new column, injured_new, appeared at the end with the exact same contents as the variable injured. We will now change those ‘0’ and ‘1’ values.
A function to change values is as_factor() from the haven package. This function takes the labels assigned to the values of the variable, and changes those original values into these very labels.
# Remember: You can check what package each function we learn today belongs to by referring to the top of each online lesson, under 'Functions Introduced'
ncvs$injury_r <- as_factor(ncvs$injured)In the data frame ncvs, you will see this new column injured_r. If we make the frequency table with this new variable, we see that the values are readily understandable as ‘uninjured’ and ‘injured’:
table(ncvs$injury_r)##
## uninjured injured
## 16160 7809This a lot easier than ‘VLOOKUP’ from last semester!
2.4.1.5 Activity 5: Creating a composite variable from more than 1 existing variable
We turn to Scenario 2: we want to create a new variable in our ncvs data frame that indicates the severity of the victimization experienced by the respondent.
That severity will be measured by two variables: (1) whether the offender had a weapon and (2) whether the victim sustained an injury during their victimization. These are not necessarily the best variables to use in measuring victimization severity; this example, however, should illustrate how you might combine variables to create a new one.
Before we do this, we need to know if we can actually do so by getting to know those variables of interest. By using the function count(), we get a good sense of what the values represent and the number of respondents in each of those values for both variables.
# Is the appropriate package, 'dplyr', loaded?
# Using count ( ) for ‘injured’ and ‘weaponpresent’
count(ncvs, injured)## # A tibble: 2 x 2
## injured n
## * <dbl+lbl> <int>
## 1 0 [uninjured] 16160
## 2 1 [injured] 7809count(ncvs, weaponpresent)## # A tibble: 3 x 2
## weaponpresent n
## * <dbl> <int>
## 1 0 15814
## 2 1 6652
## 3 NA 1503This function tells us that injured, a binary variable, is stored as numbers, where the 0 value means the victim was uninjured and the 1 value means they were injured. Also, the weaponpresent variable is (should be) a binary variable stored as numbers. Here, more victims report that the offender did not use a weapon during the offence (n= 15,814) as opposed to using one (n= 6652). But there are also a number of missing values for this question (n= 1503).
Now what if we wanted to combine these, so we can have a score of severity, which takes into consideration presence of weapon and injury?
There is a particular function from the dplyr package that is very handy for creating a new variable from more than 1 variable. It is called mutate. The mutate() function will create a new column in our data frame that comprises the sum of both of these variables, keeping the old variables too:
# Create the new variable with mutate:
# 1. The first argument inside the `mutate` function is the data frame into which we want to create the new variable
# 2. After the comma, we insert the equation that adds together the variables 'injured' and 'weaponpresent' to create the new variable called 'severity'
# 3. This new variable is saved in the data frame `ncvs` (to do so, it overwrites the old version of 'ncvs')
ncvs <- mutate(ncvs, severity = injured + weaponpresent)Now view the data frame to see the new variable severity. The severity variable is ordinal, where ‘0’ is the least severe (neither a weapon was used nor the victim injured), ‘1’ is more severe (either the offender wielded a weapon or the victim reported being injured), and ‘2’ is the most severe (the respondent reported being injured and the offender had a weapon).
Let us see the new variable in the frequency table:
table(ncvs$severity)##
## 0 1 2
## 9945 10862 1659You can then add value labels to reflect your understanding of the summed scores. To do so, you can over-write the existing severity variable (instead of making an additional duplicate variable).
You do so by specifying it on the left side of the <- (assignment operator). Then, on the right side, you use the recode() function. Inside the brackets of the recode() function, we specify the variable we want to change, and then we follow with a list of values. Notice that the numbers must be between the crooked quote marks ````:
ncvs$severity <- recode(ncvs$severity, `0` = "not at all severe", `1` = "somewhat severe", `2` = "very severe")View this new version of the severity variable in a frequency table:
table(ncvs$severity)##
## not at all severe somewhat severe very severe
## 9945 10862 1659The above example was simple, but often, we will want to make more complex combinations of variables. This is known as recoding. And it will constitute our next activity.
2.4.1.6 Activity 6: Recoding
Now to Scenario 3: we want to turn the variable relationship into a binary variable called notstranger whereby the offender was either a stranger (0) or was known to the victim (1).
First, we use the table() function to create a frequency table for relationship, and it has four categories:
table(ncvs$relationship)##
## 0 1 2 3
## 6547 2950 4576 9227What do these categories mean? We can use the as_factor() function from the haven package to find out:
table(as_factor(ncvs$relationship))##
## stranger slightly known casual acquiant well known Don't know
## 6547 2950 4576 9227 0There are four categories of relationship in addition to a ‘don’t know’ category, but there are no observations in it.
We want to turn this into a binary variable. So let us use mutate() and a new function called case_when().
Think of case_when() as an ‘if’ logical statement. It allows us to make changes to a variable that are conditional on some requirement. For example, we specify that values greater than ‘0’ (values 1 to 3) mean ‘not a stranger’ and values equal to ‘0’ mean ‘stranger’:
ncvs <- mutate(ncvs,
notstranger = case_when(
relationship == 0 ~ "Stranger",
relationship > 0 ~ "Not a stranger"))To verify that we have recoded a new binary variable:
table(ncvs$notstranger)##
## Not a stranger Stranger
## 16753 6547It seems that most victimisation is perpetrated by non-strangers!
2.4.2 Labels
Variables sometimes come with labels – these are very brief descriptions of the variable itself and what its values are. We are familiar with variable labels because of our previous activities. Now, value labels are very useful when we have a nominal or ordinal level variable in our dataset that has been assigned numeric values. To have a look at what are your variable and value labels, use the function attributes():
attributes(ncvs$injured)## $label
## [1] "Victim Sustained Injuries During Vicitmization"
##
## $format.spss
## [1] "F8.2"
##
## $display_width
## [1] 10
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## uninjured injured
## 0 1# You can also use var_label() and get_labels() too, but attributes() shows both types of labelsReturning to a familiar variable, injured, the output in the console shows that ‘uninjured’ is labelled ‘0’ and ‘injured’ is labelled ‘1’. Maybe, though, you do not like the labels that are attached to the variable values. Perhaps they do not make sense or they do not help you to understand better what this variable measures. If so, we can remove and change the labels.
2.4.2.1 Activity 7: Removing labels
We return to the injured variable from the ncvs dataframe. We, again, are going to make a duplicate variable of injured to learn how to remove and add labels. We do this because it is good practice to leave your original variables alone in case you need to go back to them.
# Make a new variable that is a duplicate of the original one, but naming it ‘injured_no_labels’
ncvs$injured_no_labels <- ncvs$injured
attributes(ncvs$injured_no_labels)## $label
## [1] "Victim Sustained Injuries During Vicitmization"
##
## $format.spss
## [1] "F8.2"
##
## $display_width
## [1] 10
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## uninjured injured
## 0 1To remove labels, we will need to load two new packages: labelled and sjlabelled. Can you do that?
After loading the two new packages, we remove variable and value labels:
# Remove variable labels
ncvs$injured_no_labels <- remove_var_label(ncvs$injured_no_labels)
# Check that they were removed
var_label(ncvs$injured_no_labels)## NULL# Remove value labels
ncvs$injured_no_labels <- remove_labels(ncvs$injured_no_labels, labels = c(1:2))
# Check that they were removed
get_labels(ncvs$injured_no_labels)## NULLNow to add a label:
# Add variable label
var_label(ncvs$injured_no_labels) <- "Whether Victim Sustained Injuries"
# Check that they were added
var_label(ncvs$injured_no_labels)## [1] "Whether Victim Sustained Injuries"# Add value labels
ncvs$injured_no_labels <-add_labels(ncvs$injured_no_labels, labels = c(`uninjured` = 0, `injured` = 1))
# Check that they were added
get_labels(ncvs$injured_no_labels)## [1] "uninjured" "injured"Nothing to add in the googledoc so far, since Activity 4, so onto the next activity.
2.4.2.2 Note: pipes
![]()
In R, %>% represents a pipe operator. This is a nifty shortcut in R coding. It is in reference to René Magritte’s The Treachery of Images. The pipe operator means that we only need to specify the data frame object once at the beginning as opposed to typing out the name of the data frame repeatedly. In all subsequent functions, the object is ‘piped’ through. If you were to read the code out loud, you might say ‘and then’ whenever you come across the pipe operator. We will use this now.
2.4.3 Subsetting
2.4.3.1 Activity 8: Ways to subset data
Through tidyverse functions, we can subset our data frames or vectors based on some criteria. Using the function select(), we can subset variables by number or name:
# Using select () to subset by the first two variables
ncvs_df_1 <- ncvs %>% select(1:2) If we wanted to select only the variables injured, weaponpresent, and severity:
# Using select () to subset by three select variables
ncvs_df_2 <- ncvs %>% select(injured, weaponpresent, severity) Using the function slice(), we can subset rows by number. To get only the first row:
# Get the first row
first_row_of_ncvs <- ncvs %>% slice(1) To get more rows, you can use the ‘from:to’ notation. To get the first two rows, for example, you say ‘from 1 to 2’, that is ‘1:2’:
# Get the first two rows
first_two_rows_of_ncvs <- ncvs %>% slice(1:2) You can subset select rows and columns by taking slice() and combining it with select(). For example:
# Get the first two variables and first two rows
first_two_rows_cols <- ncvs %>% select(1:2) %>% slice(1:2)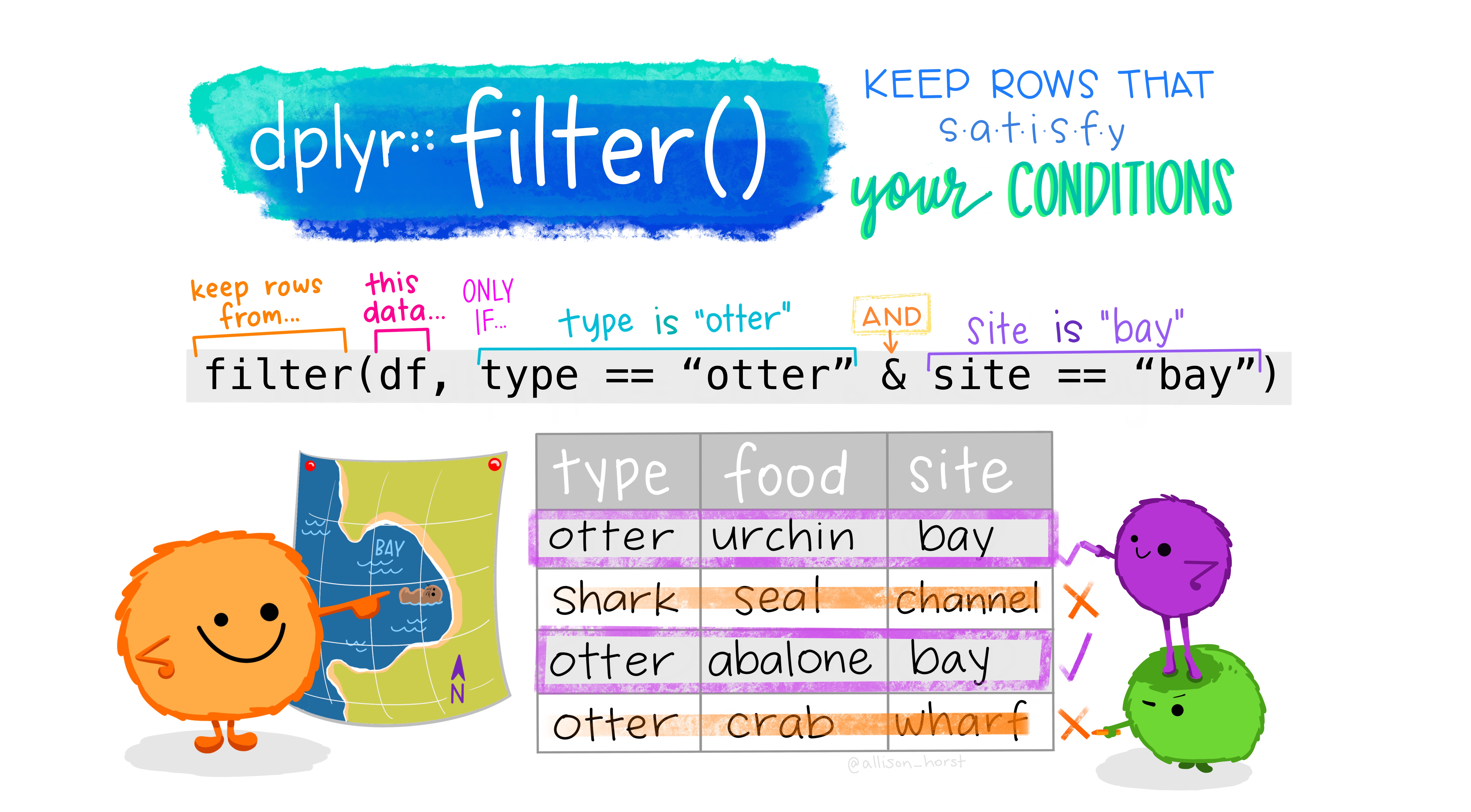
Figure 2.11 Filter by Allison Horst
Use the filter() function to subset observations (i.e., rows) based on conditions. For example, we only want those for which the injured variable was equal to 1, so we run:
only_injured <- ncvs %>% filter(injured == 1)These filters can be combined using conditions and (&) and or (|) except we call this subset of the data frame ‘knew_of_and_injured’:
# We want a subset called 'knew_of_and_injured' which comprises responses greater than 0 in the 'relationship' variable and responses equal to 1 in the 'injured' variable
knew_of_and_injured <- ncvs %>%
filter(relationship > 0 & injured == 1)Say if we wanted the first five rows of knew_of_and_injured. How would we do that? In your group googledoc, type out the code you think will help you create a (sub-)subset knew_of_and_injured of its first five rows. Call this new subset ‘injuredfiveknew’.
2.4.3.2 Activity 9: Subsetting, the Sequel
We now have a subset called injuredfiveknew. Say we only want to keep the variables V3014 (age) and V3018 (sex). How would you make an object that only contains these two variables from injuredfiveknew?
Recall that you would need to use the function select()to select variables. But in this example, instead of inserting ’ : ’ like in the previous code, you would need to insert a ‘,’. Understanding what ‘:’ means and viewing the order of the variables in injuredfiveknew will give you insight into why.
In your group googledoc sheet, write out the code that you would use to do so. Name this new object that contains the two variables five_ageandincome
2.5 SUMMARY
Today you were further introduced to tidyverse packages that helped you to tidy your data. First, we learned to put our work into a project and then how to import data using a package called haven. Whenever we specify a data frame, we learned a nifty short-cut: the pipe operator - %>% - which allows us to specify the data frame only once when we code.
Our three main topics today had to do with helping us tidy. There was a lot of data wrangling too. One topic were the variables themselves where we learned about the factor and numeric classes, and how to make and recode new variables. Two, we learned how to remove and add variable and value labels so that we can understand what our variables are measuring. Three, we then learned to subset our data, whereby we make new dataframes that include only the columns – variables – or rows – observations – we want. We tidied our data using the TIDYVERSE WAY!
P.S. Well done today, to get through all this. What you are learning now will serve as the building blocks for your later data analysis, and we recognise it is all new and scary. But keep practicing, and you will get the hang of this in no time! And of course: don’t forget to do your homework!
2.5.1 Answers to activities (if applicable)
- N/A
- 23,969 entries and 47 columns
- numeric (but is this correct?)- class(ncvs$weaponpresent)
- N/A
- N/A
- N/A
- N/A
- injuredfiveknew <- KnewOfandInjured %>% slice(1:5)
- five_ageandincome <- injuredfiveknew %>% select(4,6)